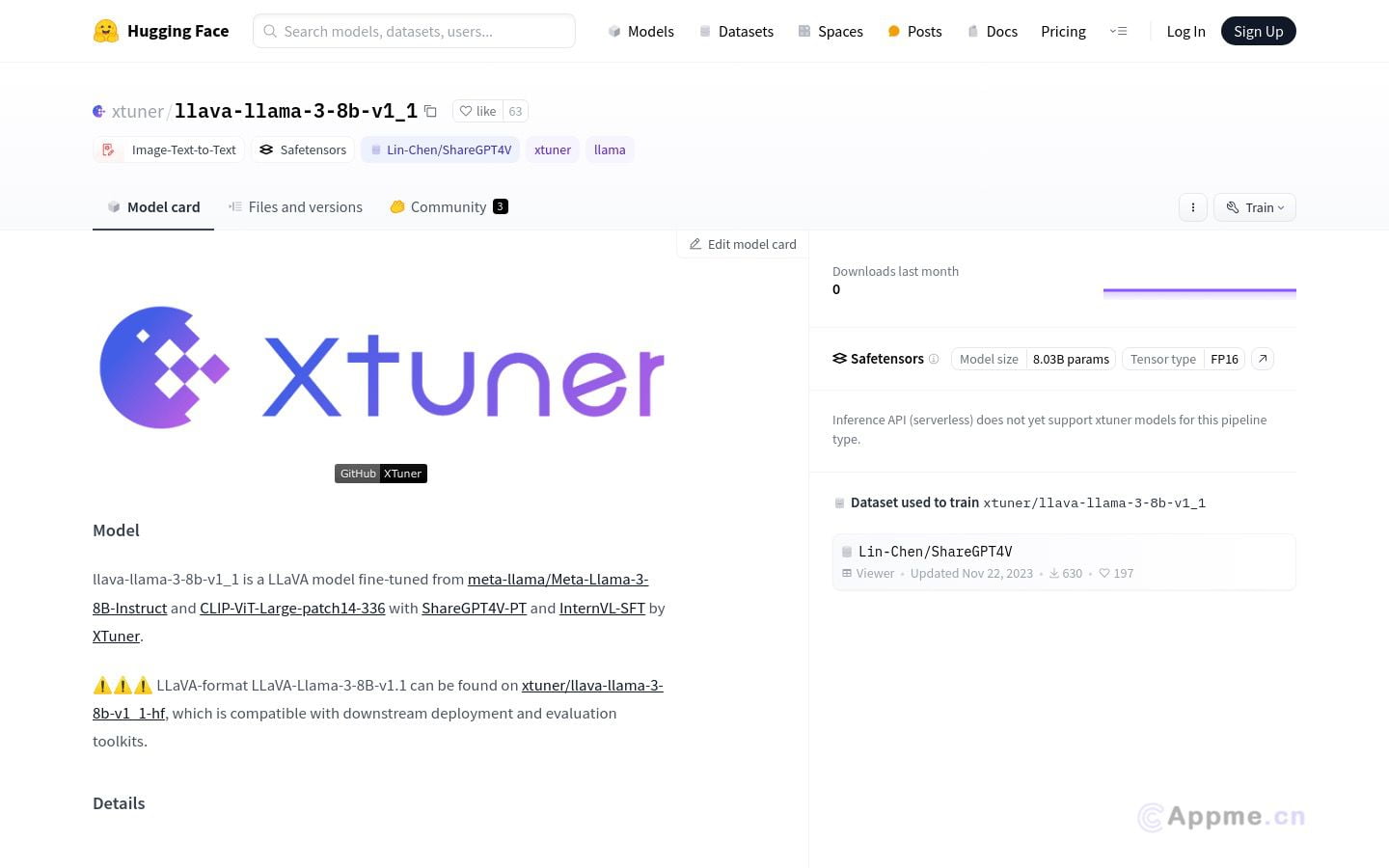
llava-llama-3-8b-v1_1是一款由XTuner优化的先进AI模型,专门设计用于处理图像和文本的复杂交互。该模型基于Meta-Llama-3-8B-Instruct和CLIP-ViT-Large-patch14-336,通过ShareGPT4V-PT和InternVL-SFT进行了精细微调,具备强大的多模态学习能力。它能够高效地理解和分析图像内容,同时结合文本信息进行深度推理和生成。这使得llava-llama-3-8b-v1_1在图像描述、视觉问答、图文匹配等任务中表现出色。该模型尤其适合研究人员、开发者和数据科学家使用,可以轻松集成到各种下游应用中。对于需要处理大量图像和文本数据的企业和机构,llava-llama-3-8b-v1_1能够提供准确、高效的分析结果,大幅提升工作效率和决策质量。
People Also Like