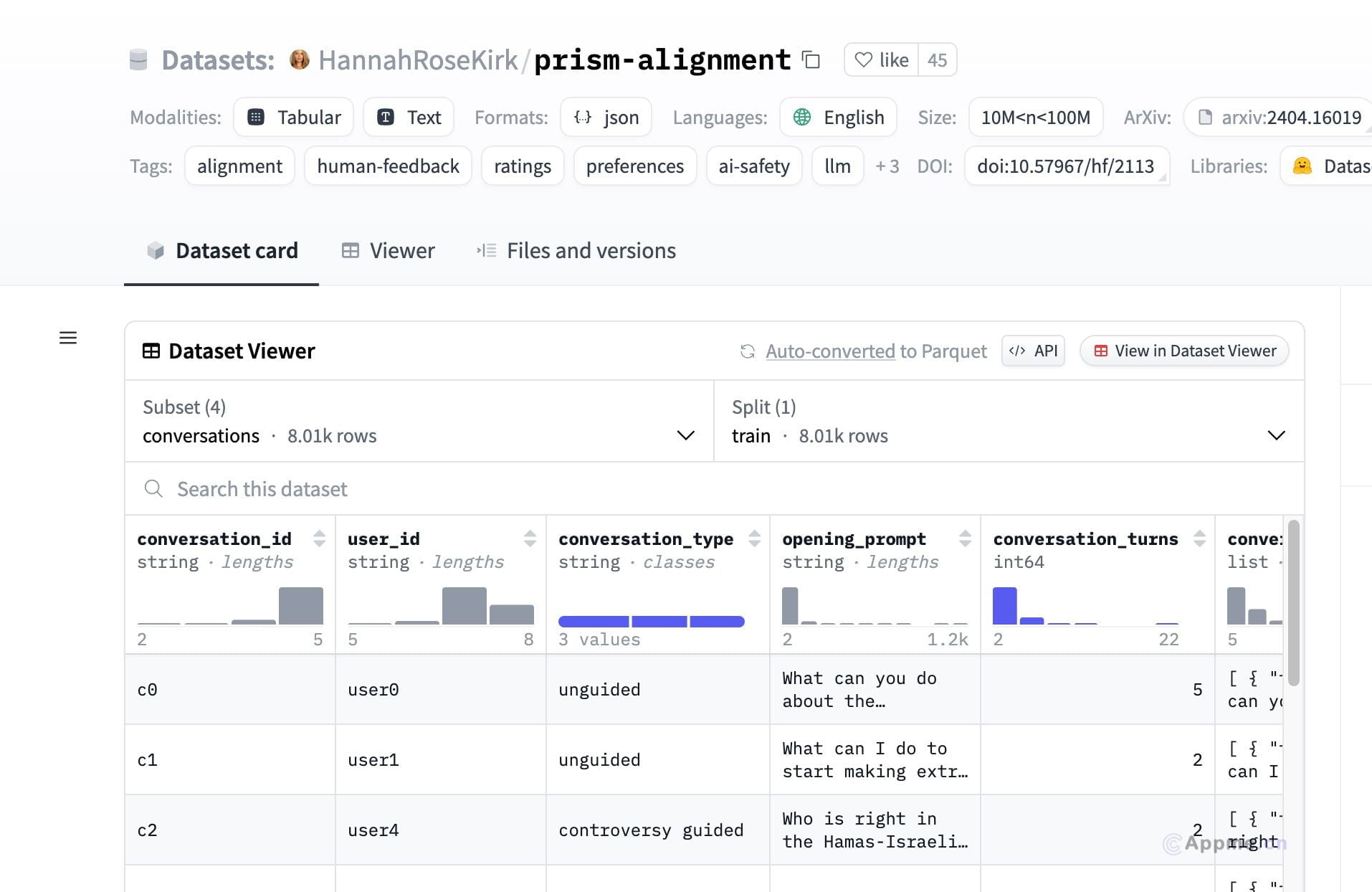
prism-alignment 是一个由 HannahRoseKirk 创建的数据集,专注于研究大型语言模型(LLMs)的偏好和价值观对齐问题。数据集通过调查问卷和与语言模型的多轮对话,收集了来自不同国家和文化背景的参与者对模型回答的评分和反馈。这些数据对于理解和改进人工智能的价值观对齐至关重要。
需求人群: "prism-alignment 数据集的目标受众主要是自然语言处理、人工智能和社会科学领域的研究人员和学生。它适合那些对探索和改进 AI 价值观对齐、进行跨文化研究或开发更符合人类价值观的对话代理感兴趣的用户。" 使用场景示例: 研究人员使用 prism-alignment 数据集来分析不同文化背景下人们对 AI 行为的偏好。学生利用该数据集进行课程项目,探索 AI 伦理和价值观问题。开发者利用数据集中的反馈来训练和优化对话系统,使其更加符合用户的期望和价值观。 产品特色: 包含多种模态,如表格和文本,以及多种格式,如 JSON。涵盖英语语言数据,大小在10M至100M之间。数据集带有详细的标签,如对齐、人类反馈、偏好、AI 安全等。支持使用 pandas 和 mlcroissant 等库进行数据处理。遵循 Creative Commons 许可协议,鼓励研究和教育使用。数据集经过伦理审查,并由多方资助和支持。 使用教程: 第一步:访问 Hugging Face 上的 prism-alignment 数据集页面。第二步:下载数据集,根据需要选择合适的格式和子集。第三步:使用 pandas 或 mlcroissant 等库对数据进行加载和初步探索。第四步:根据研究目的,筛选和分析数据集中的相关变量。第五步:利用数据集中的反馈信息来指导 AI 模型的训练和优化。第六步:在研究或项目中应用所得结论,改进 AI 的价值观对齐。第七步:遵循数据集的使用协议,正确引用数据集来源。 展开 浏览量:7 s1785318098921236 打开站点