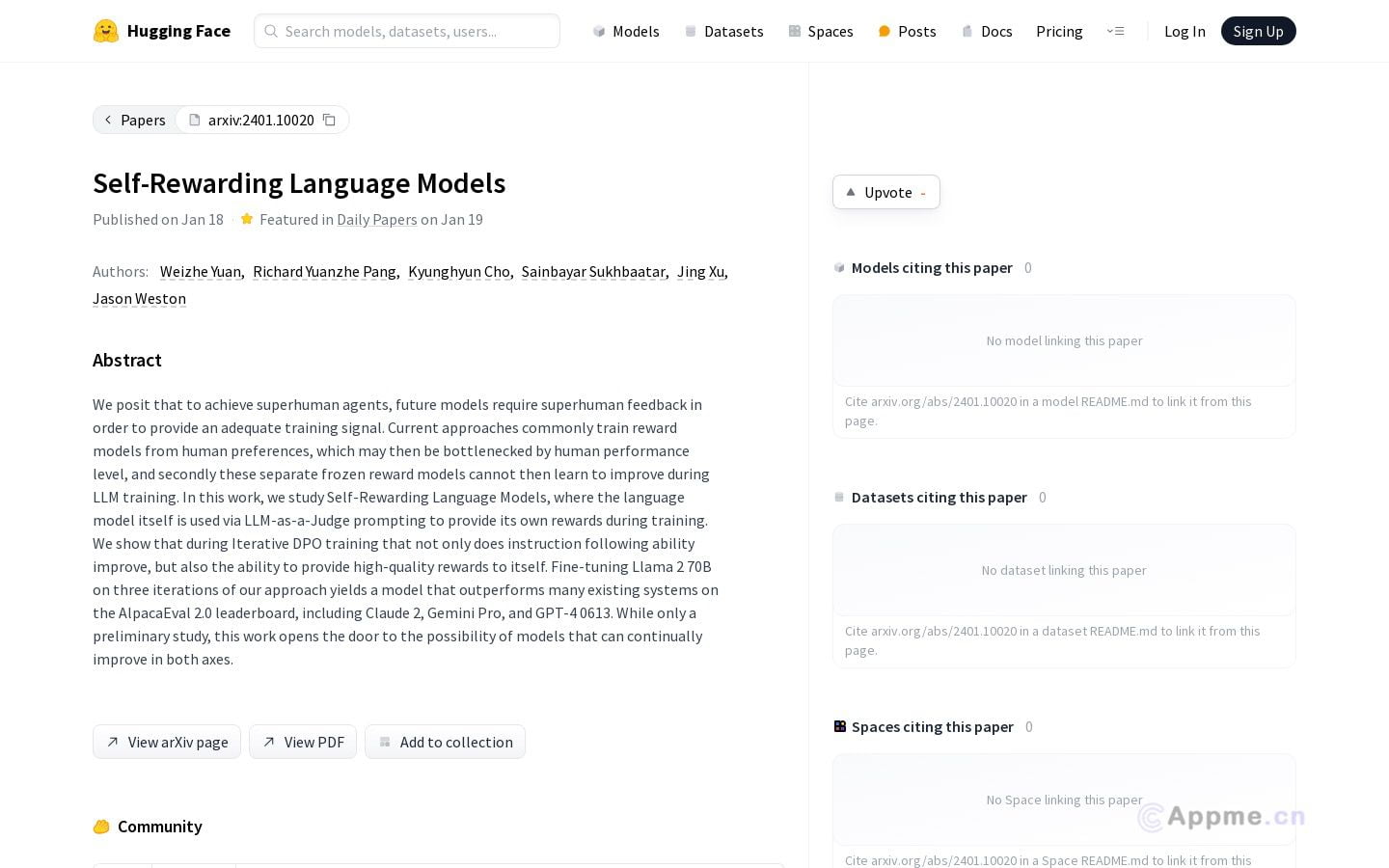
Self-Rewarding Language Models是一种创新的自然语言处理工具,通过LLM作为裁判,利用自身提供的奖励信号进行训练。它采用迭代的DPO训练方法,不仅提高了模型遵循指令的能力,还能生成高质量的自我奖励。经过三次Fine-tuning,该模型在AlpacaEval 2.0排行榜上的表现超越了多个知名系统,包括Claude 2、Gemini Pro和GPT-4 0613。
这款工具特别适合需要高质量自然语言生成的场景,如聊天机器人、写作辅助工具等。它为研究人员、开发者和企业提供了一个强大的语言模型训练平台,能够显著提升文本生成的准确性和创造性。通过自我奖励机制,该工具为语言模型的持续改进开辟了新的可能性,为用户带来更智能、更自然的语言处理体验。