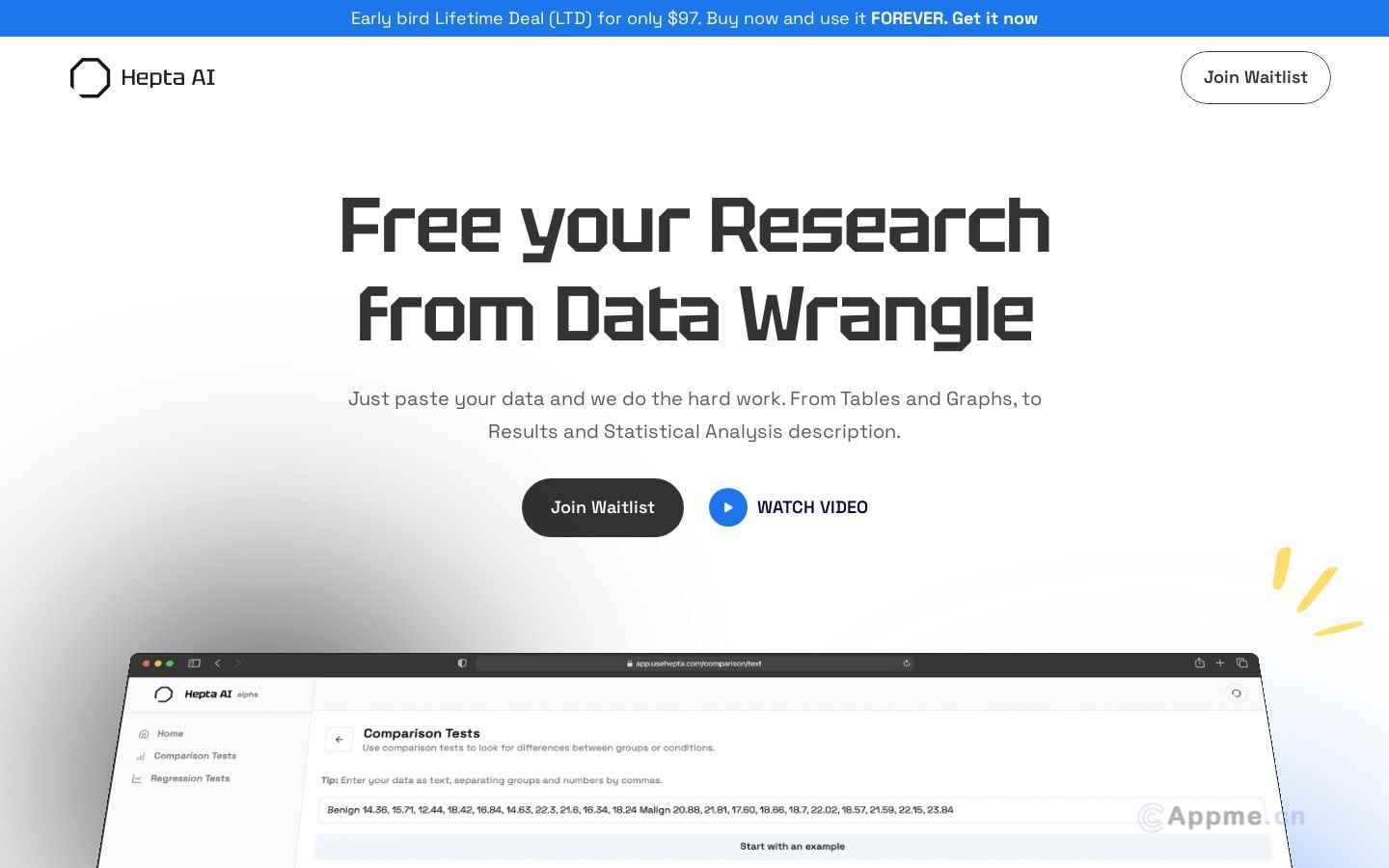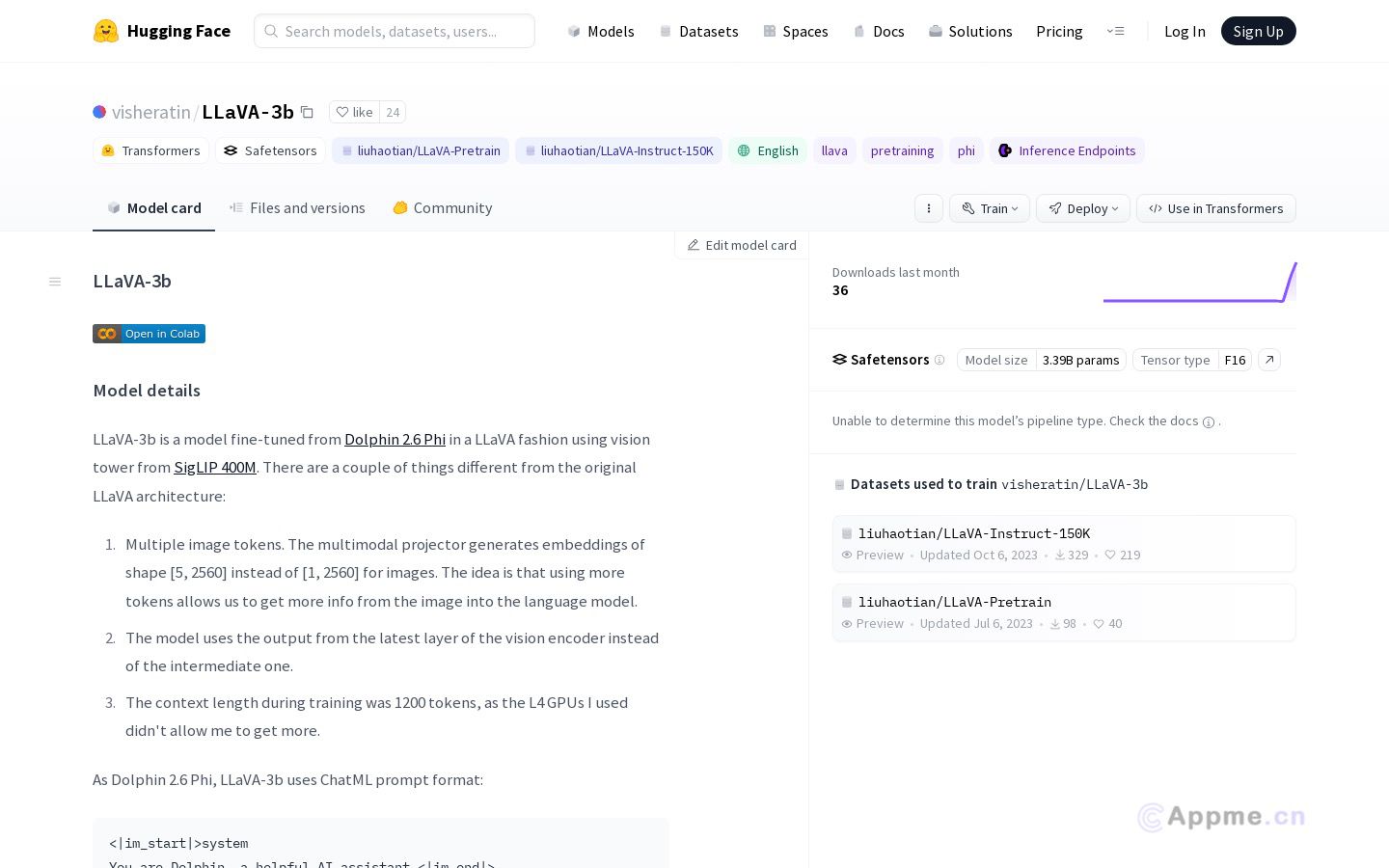
LLaVA-3b是一种基于Dolphin 2.6 Phi进行微调的模型,使用SigLIP 400M的视觉塔以LLaVA方式进行微调。模型具有多个图像标记、使用视觉编码器的最新层输出等特点。此模型基于Phi-2,受微软研究许可证约束,禁止商业使用。感谢ML Collective提供的计算资源积分。
需求人群: "LLaVA-3b可用于图像描述生成、视觉问答等应用场景。"

LLaVA-3b是一种基于Dolphin 2.6 Phi进行微调的模型,使用SigLIP 400M的视觉塔以LLaVA方式进行微调。模型具有多个图像标记、使用视觉编码器的最新层输出等特点。此模型基于Phi-2,受微软研究许可证约束,禁止商业使用。感谢ML Collective提供的计算资源积分。
需求人群: "LLaVA-3b可用于图像描述生成、视觉问答等应用场景。"