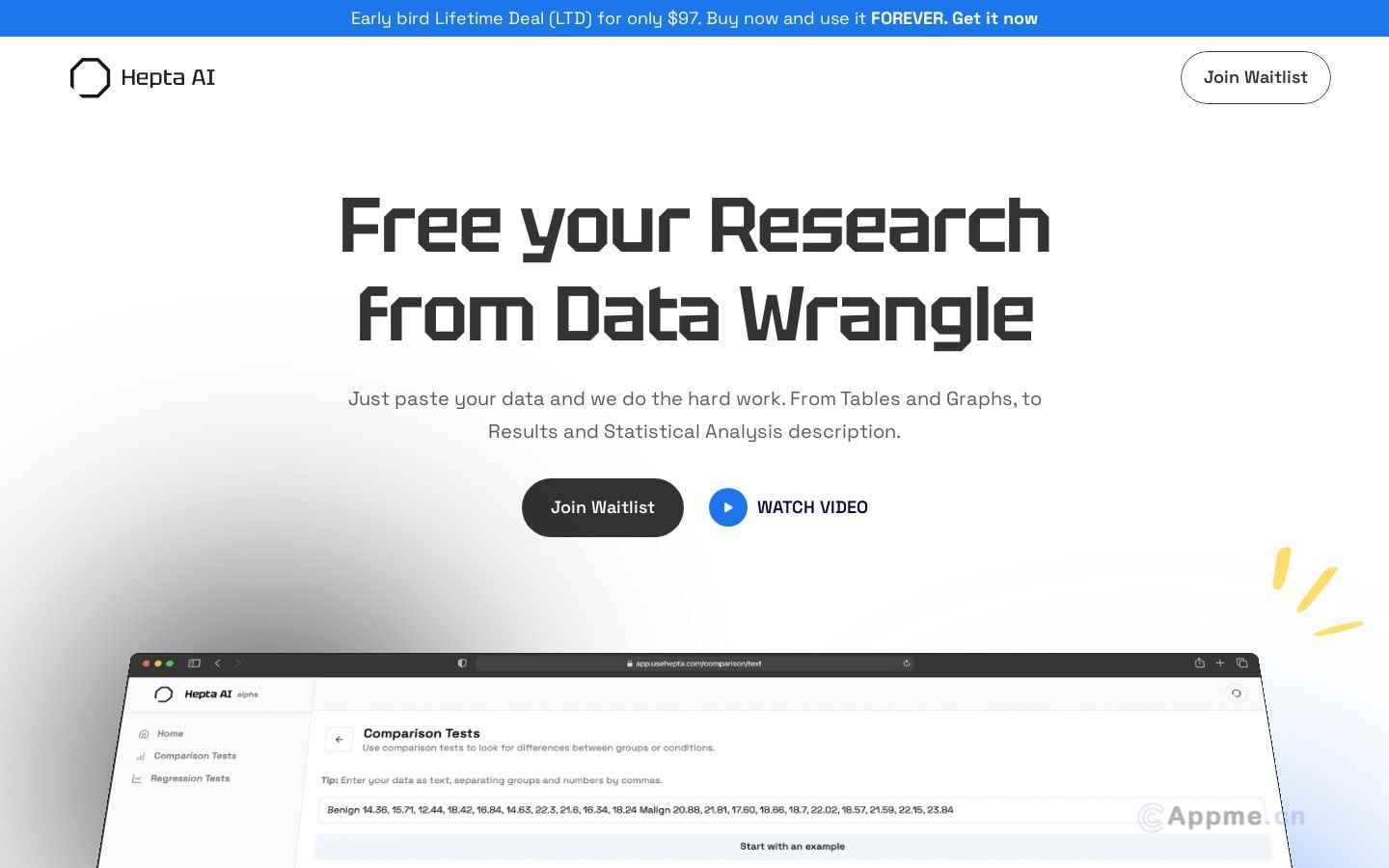
MNBVC是一个专为AI提供丰富中文语料的开源项目。它收集了包括新闻、文学、网络用语等多种形式的纯文本中文数据,涵盖主流文化和小众内容。该项目的主要特点是数据规模大、类型多样,能够满足各种中文自然语言处理任务的需求。MNBVC特别适合自然语言处理研究者、中文机器学习开发者以及需要大量中文语料的AI项目使用。它可用于训练中文聊天机器人、支持文本挖掘和情感分析,以及作为中文自然语言理解模型的训练基础。通过提供这些丰富的语料资源,MNBVC有助于促进中文AI技术的发展,为研究人员和开发者提供了宝贵的数据支持,推动了中文自然语言处理领域的进步。