
数据集

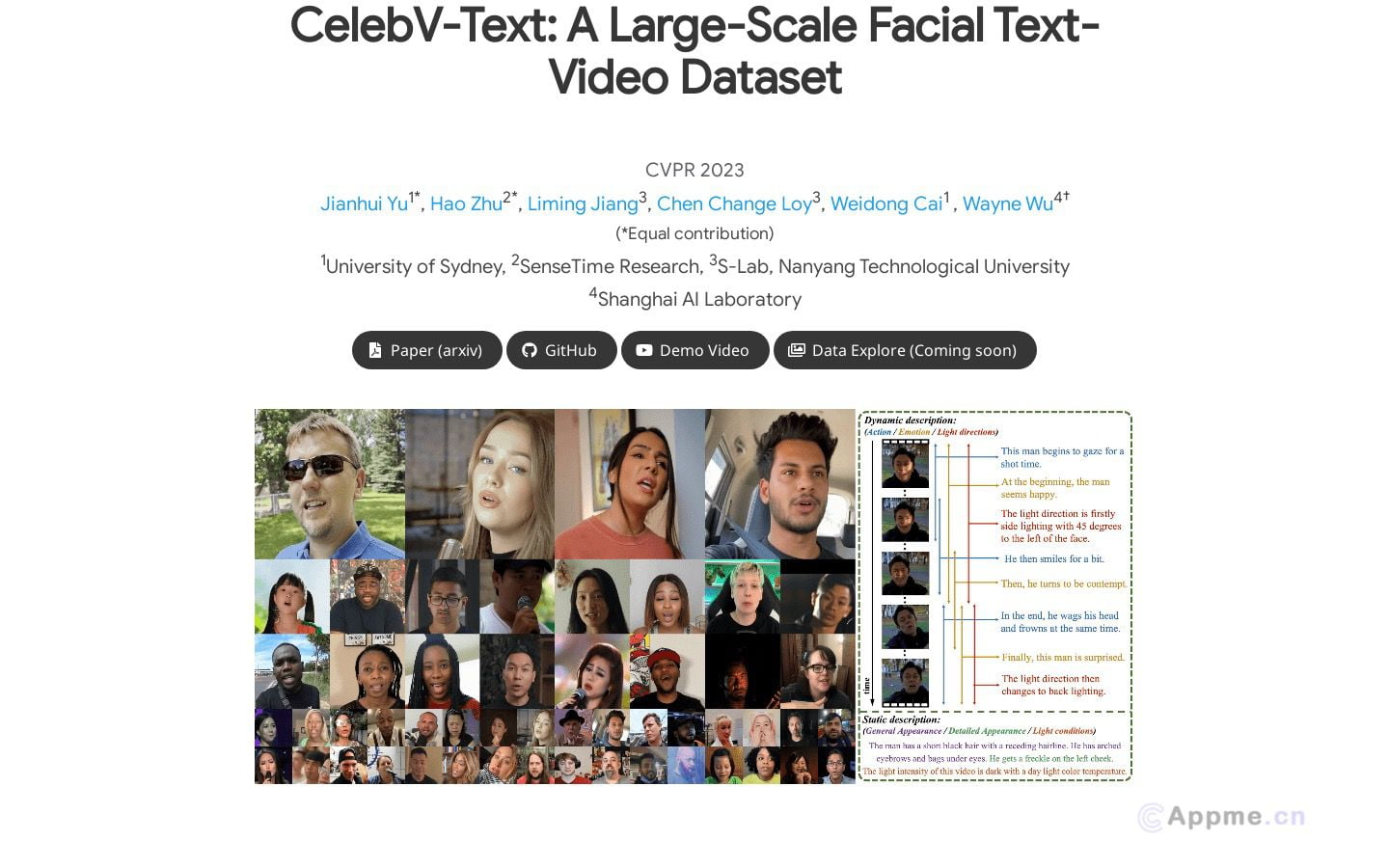
数据集是人工智能和机器学习领域的基石,为各类AI模型的训练和评估提供了必不可少的原材料。高质量的数据集涵盖了文本、图像、音频、视频等多种形式,适用于自然语言处理、计算机视觉、语音识别等广泛应用场景。
代表性数据集如ImageNet和COCO在计算机视觉领域影响深远,而GLUE和SQuAD则是自然语言处理的重要基准。除公开数据集外,还有众多专业数据标注工具和平台,如Labelbox和Supervisely,可用于构建定制化数据集。
数据集的核心优势在于其规模、多样性和标注质量,直接影响模型的性能和泛化能力。随着AI技术的发展,多模态、跨语言和动态更新的数据集正成为新趋势。未来,构建更大规模、更高质量的数据集,以及开发更智能的数据处理技术,将持续推动AI领域的创新和进步。
Altern
Ai网站最新工具Altern,Altern 不仅仅是一个目录,更是一个 AI 爱好者社区驱动的中心。在这里可以发现最新的 AI 产品、工具、模型、数据集、新闻通讯和 YouTube 频道,全部集中在一个地方。加入我们不断增长的社区,分享您的见解,为最佳资源投票,编写评论,并与其他 AI 迷联络。您进入 AI 内部的旅程从 altern.ai 开始!