
扩散模型

Flash Diffusion - 革命性AI图像生成工具,仅需少量步骤即可生成惊艳高清图像!相比同类产品快10倍,参数量减少90%,成本降低80%。Flash Diffusion在COCO数据集基准测试中脱颖而出,实现了最先进的图像处理性能。无论是文本生成图像、图像修复还是超分辨率,Flash Diffusion都能轻松应对。现在购买即享8折优惠,你还在等什么?立即体验Flash Diffusion的强大魅力,让你的创意触手可及!
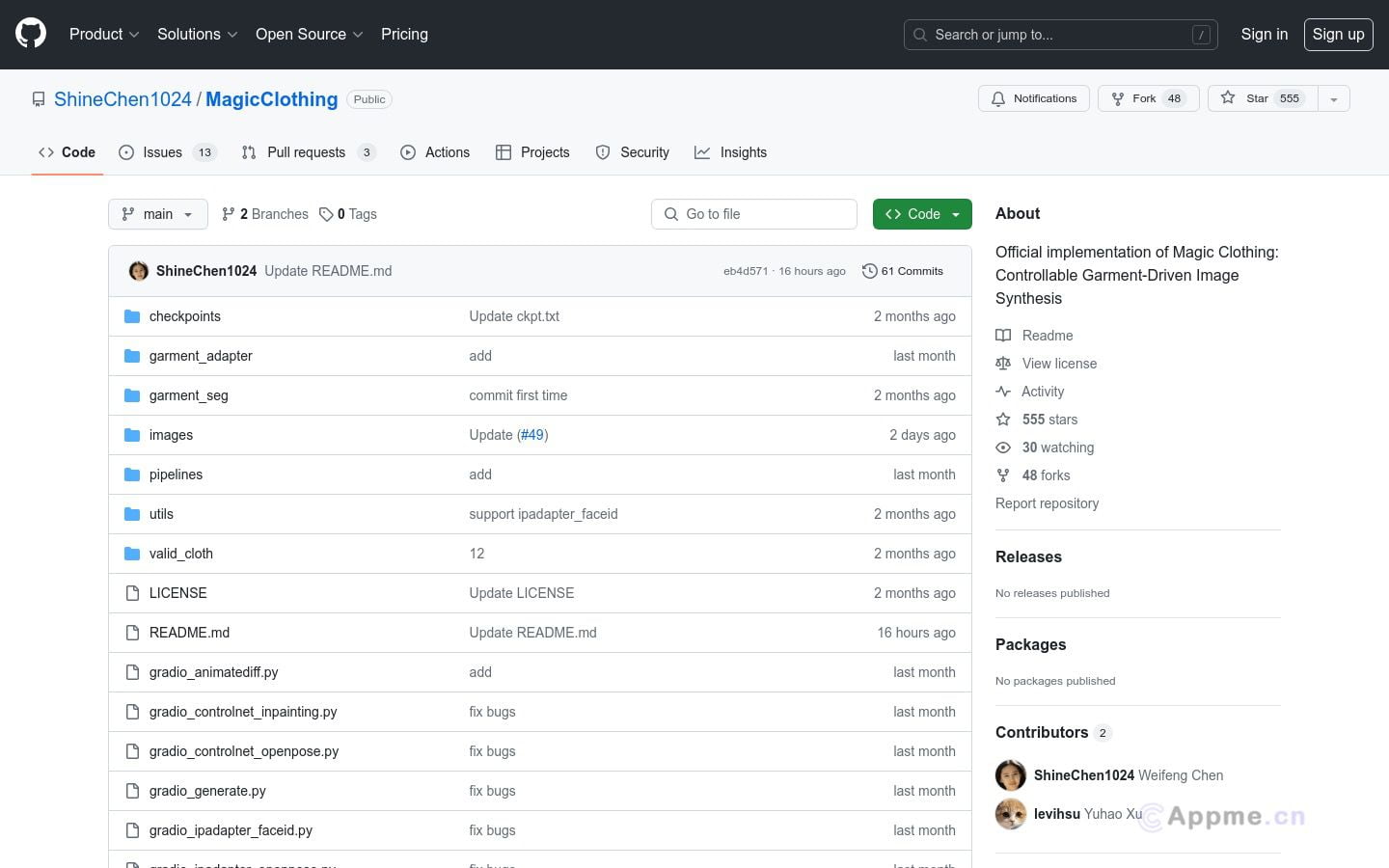
Ai模型最新工具MagicClothing,MagicClothing是一种基于潜在扩散模型(LDM)的新型网络架构,专门用于服装驱动的图像合成任务。它能够根据文本提示生成穿着特定服装的定制化角色图像,同时确保服装细节的保留和对文本提示的忠实呈现。该系统通过服装特征提取器和自注意力融合技术,实现了高度的图像可控性,并且可以与ControlNet和IP-Adapter等其他技术结合使用,以提升角色的多样性和可控性。此外,还开发了匹配点LPIPS(MP-LPIPS)评估指标,用于评价生成图像与原始服装的一致性。
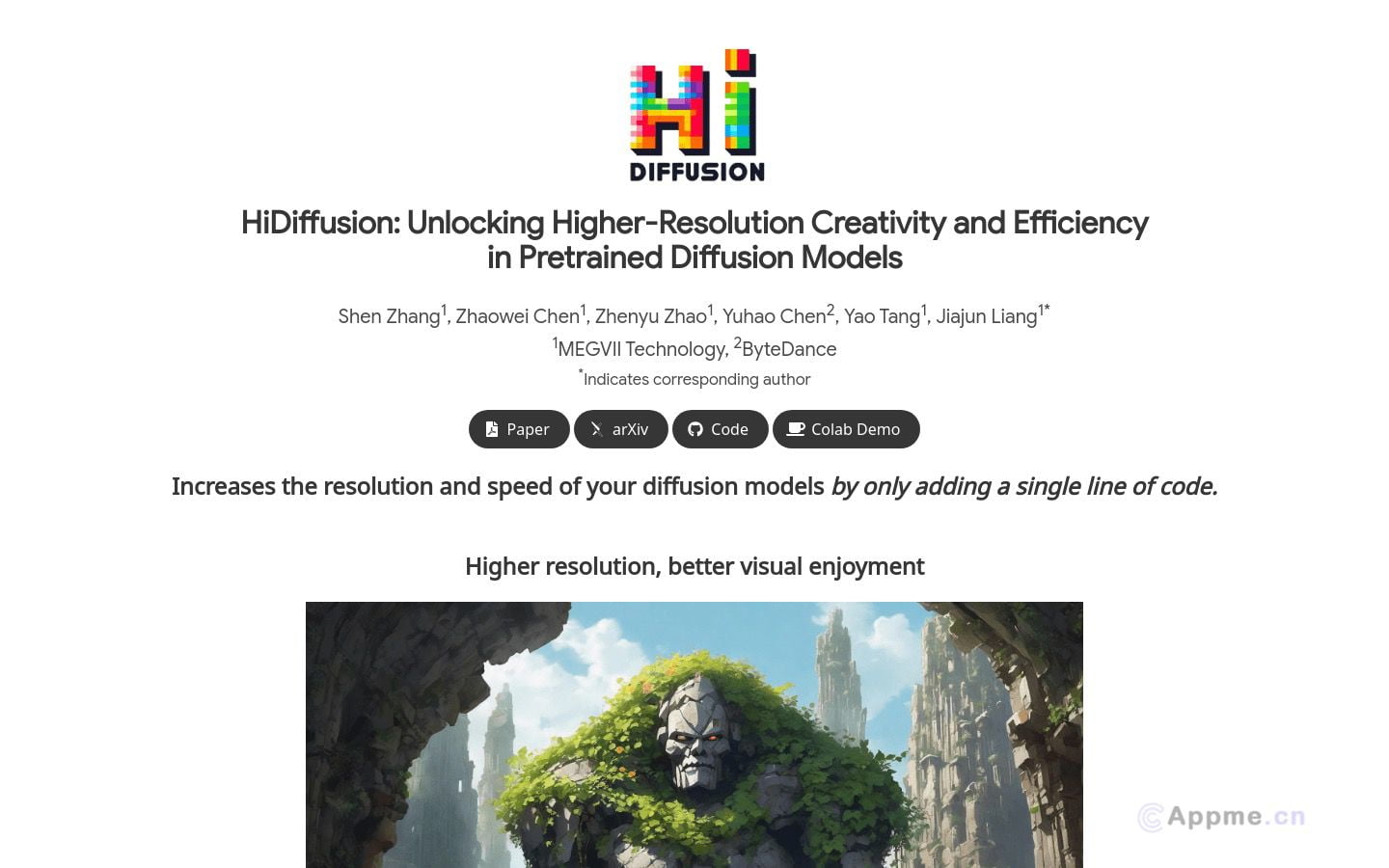
Ai模型最新工具HiDiffusion,HiDiffusion是一个预训练扩散模型,通过仅添加一行代码即可提高扩散模型的分辨率和速度。该模型通过Resolution-Aware U-Net (RAU-Net)和Modified Shifted Window Multi-head Self-Attention (MSW-MSA)技术,动态调整特征图大小以解决对象复制问题,并优化窗口注意力以减少计算量。HiDiffusion能够将图像生成分辨率扩展到4096×4096,同时保持1.5-6倍于以往方法的推理速度。

Ai网站最新工具MagicAnimate Playground,MagicAnimate是一款基于扩散模型的先进框架,用于人体图像动画。它能够从单张图像和动态视频生成动画视频,具有时域一致性,能够保持参考图像的特征,并显著提升动画的保真度。MagicAnimate支持使用来自各种来源的动作序列进行图像动画,包括跨身份的动画和未见过的领域,如油画和电影角色。它还与DALLE3等T2I扩散模型无缝集成,可以根据文本生成的图像赋予动态动作。MagicAnimate由新加坡国立大学Show Lab和Bytedance字节跳动共同开发。

Ai模型最新工具Make-It-Vivid,Make-It-Vivid是一种创新的模型,能够根据文本指令自动生成和动画化卡通人物的3D纹理。它解决了传统方式制作3D卡通角色纹理的挑战,提供了高效、灵活的解决方案。该模型通过预训练的文本到图像扩散模型生成高质量的UV纹理图,并引入对抗性训练来增强细节。它可以根据不同的文本prompt生成各种风格的角色纹理,并将其应用到3D模型上进行动画制作,为动画、游戏等领域提供了便利的创作工具。
Ai网站最新工具Pixel-Aware Stable Diffusion,Pixel-Aware Stable Diffusion(PASD)旨在实现真实图像超分辨率和个性化风格化。通过引入像素感知交叉注意力模块,PASD使得扩散模型能够以像素级别感知图像局部结构,同时利用降级去除模块提取降级不敏感特征,与图像高层信息一起引导扩散过程。PASD可轻松集成到现有的扩散模型中,如稳定扩散。在真实图像超分辨率和个性化风格化方面的实验验证了我们提出的方法的有效性。
扩散模型是一类强大的生成式AI工具,主要用于图像、音频和视频的创作与编辑。这类模型通过逐步去噪的过程,能够从随机噪声中生成高质量、多样化的内容。其核心优势在于生成结果的逼真度和可控性,广泛应用于艺术创作、内容制作、虚拟现实等领域。
代表性工具包括Stable Diffusion和Midjourney,它们在文本到图像生成方面表现出色。此外,扩散模型还可用于图像修复、超分辨率重建等任务。
扩散模型采用深度学习技术,结合了U-Net架构和注意力机制,能够捕捉复杂的数据分布。随着模型规模和训练数据的增加,生成质量不断提升,逐渐接近真实世界的复杂度。
未来,扩散模型有望在3D内容生成、跨模态转换等方向取得突破,为创意产业带来革命性变革。随着技术的进步,我们可以期待更快速、更精确、更个性化的AI创作工具的出现。