
扩散模型

Ai模型最新工具UniAnimate,UniAnimate是一个用于人物图像动画的统一视频扩散模型框架。它通过将参考图像、姿势指导和噪声视频映射到一个共同的特征空间,以减少优化难度并确保时间上的连贯性。UniAnimate能够处理长序列,支持随机噪声输入和首帧条件输入,显著提高了生成长期视频的能力。此外,它还探索了基于状态空间模型的替代时间建模架构,以替代原始的计算密集型时间Transformer。UniAnimate在定量和定性评估中都取得了优于现有最先进技术的合成结果,并且能够通过迭代使用首帧条件策略生成高度一致的一分钟视频。
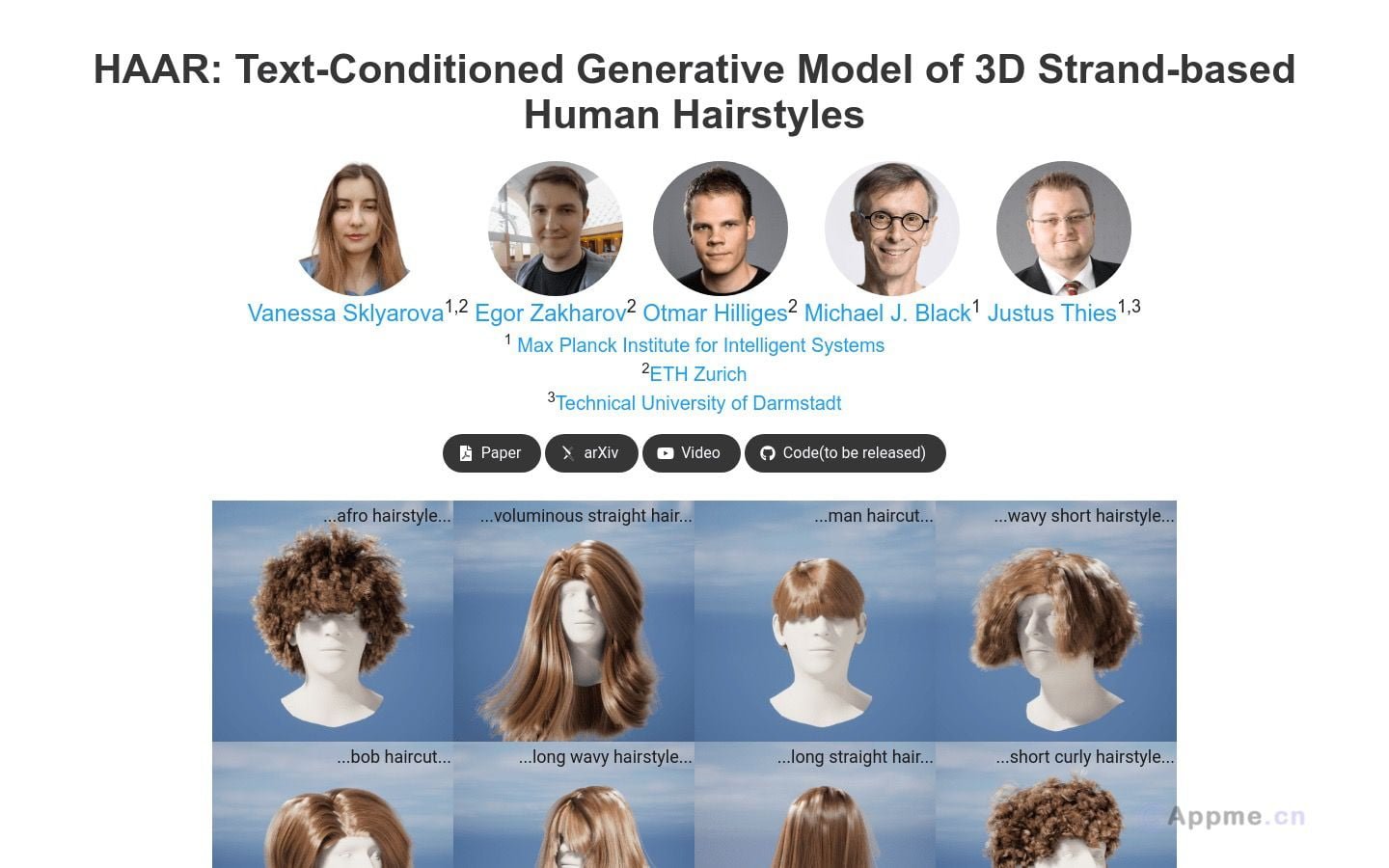
Ai网站最新工具HAAR,HAAR是一种基于文本输入的生成模型,可生成逼真的3D发型。它采用文本提示作为输入,生成准备用于各种计算机图形动画应用的3D发型资产。与当前基于AI的生成模型不同,HAAR利用3D发丝作为基础表示,通过2D视觉问答系统自动注释生成的合成发型模型。我们提出了一种基于文本引导的生成方法,使用条件扩散模型在潜在的发型UV空间生成引导发丝,并使用潜在的上采样过程重建含有数十万发丝的浓密发型,给定文本描述。生成的发型可以使用现成的计算机图形技术进行渲染。
AI产品照片生成器是一个能够在几秒钟内生成增加销售的产品图片和照片的工具。它可以将产品图片转化为专业的产品照片,提高销售效果。使用这个工具,您可以添加AI背景,避免标签模糊或形状变化的问题。我们的AI照片生成器采用了全新的文本到图像扩散模型,专门为销售进行了训练和优化。您可以从Shopify中直接生成照片,并将其与我们的视频模板配合使用。生成的产品图片可以免费使用,并且您只需要为您真正喜欢的图片付费。
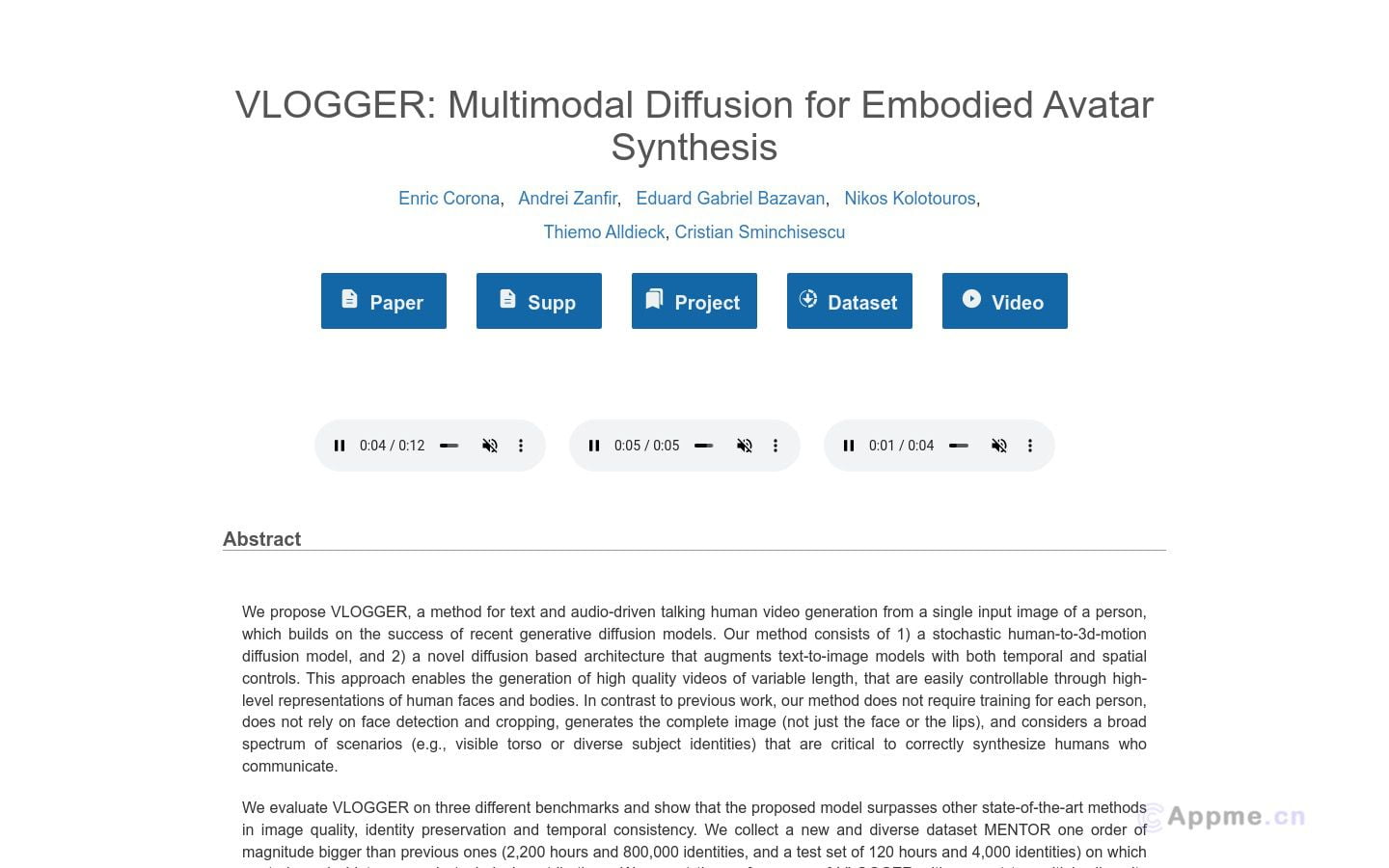
Ai网站最新工具VLOGGER,VLOGGER是一种从单张人物输入图像生成文本和音频驱动的讲话人类视频的方法,它建立在最近生成扩散模型的成功基础上。我们的方法包括1)一个随机的人类到3D运动扩散模型,以及2)一个新颖的基于扩散的架构,通过时间和空间控制增强文本到图像模型。这种方法能够生成长度可变的高质量视频,并且通过对人类面部和身体的高级表达方式轻松可控。与以前的工作不同,我们的方法不需要为每个人训练,也不依赖于人脸检测和裁剪,生成完整的图像(而不仅仅是面部或嘴唇),并考虑到正确合成交流人类所需的广泛场景(例如可见的躯干或多样性主体身份)。
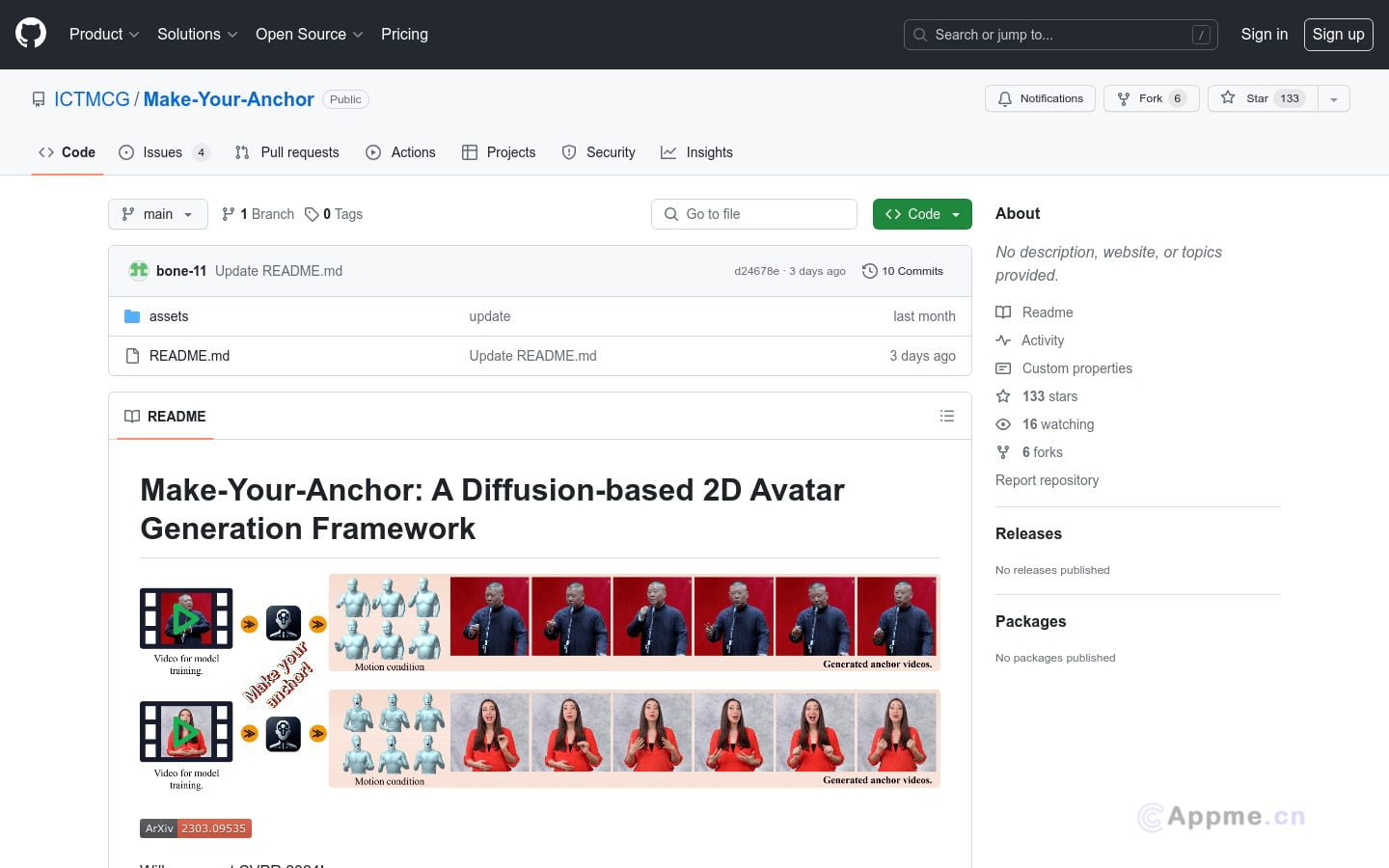
Ai模型最新工具Make-Your-Anchor,Make-Your-Anchor是一个基于扩散模型的2D虚拟形象生成框架。它只需一段1分钟左右的视频素材就可以自动生成具有精确上身和手部动作的主播风格视频。该系统采用了一种结构引导的扩散模型来将3D网格状态渲染成人物外观。通过两阶段训练策略,有效地将运动与特定外观相绑定。为了生成任意长度的时序视频,将frame-wise扩散模型的2D U-Net扩展到3D形式,并提出简单有效的批重叠时序去噪模块,从而突破推理时的视频长度限制。最后,引入了一种基于特定身份的面部增强模块,提高输出视频中面部区域的视觉质量。实验表明,该系统在视觉质量、时序一致性和身份保真度方面均优于现有技术。


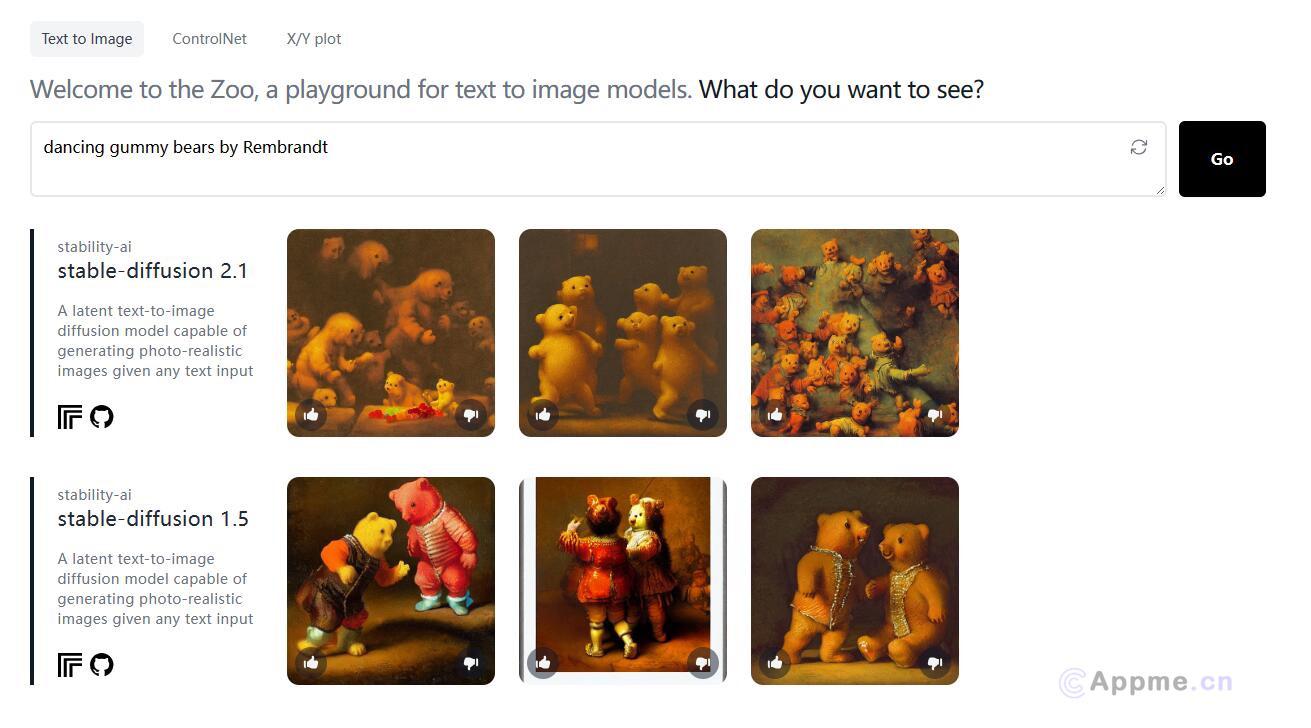
Ai模型最新工具AsyncDiff,AsyncDiff 是一种用于并行化扩散模型的异步去噪加速方案,它通过将噪声预测模型分割成多个组件并分配到不同的设备上,实现了模型的并行处理。这种方法显著减少了推理延迟,同时对生成质量的影响很小。AsyncDiff 支持多种扩散模型,包括 Stable Diffusion 2.1、Stable Diffusion 1.5、Stable Diffusion x4 Upscaler、Stable Diffusion XL 1.0、ControlNet、Stable Video Diffusion 和 AnimateDiff。
扩散模型是一类强大的生成式AI工具,主要用于图像、音频和视频的创作与编辑。这类模型通过逐步去噪的过程,能够从随机噪声中生成高质量、多样化的内容。其核心优势在于生成结果的逼真度和可控性,广泛应用于艺术创作、内容制作、虚拟现实等领域。
代表性工具包括Stable Diffusion和Midjourney,它们在文本到图像生成方面表现出色。此外,扩散模型还可用于图像修复、超分辨率重建等任务。
扩散模型采用深度学习技术,结合了U-Net架构和注意力机制,能够捕捉复杂的数据分布。随着模型规模和训练数据的增加,生成质量不断提升,逐渐接近真实世界的复杂度。
未来,扩散模型有望在3D内容生成、跨模态转换等方向取得突破,为创意产业带来革命性变革。随着技术的进步,我们可以期待更快速、更精确、更个性化的AI创作工具的出现。