
图像
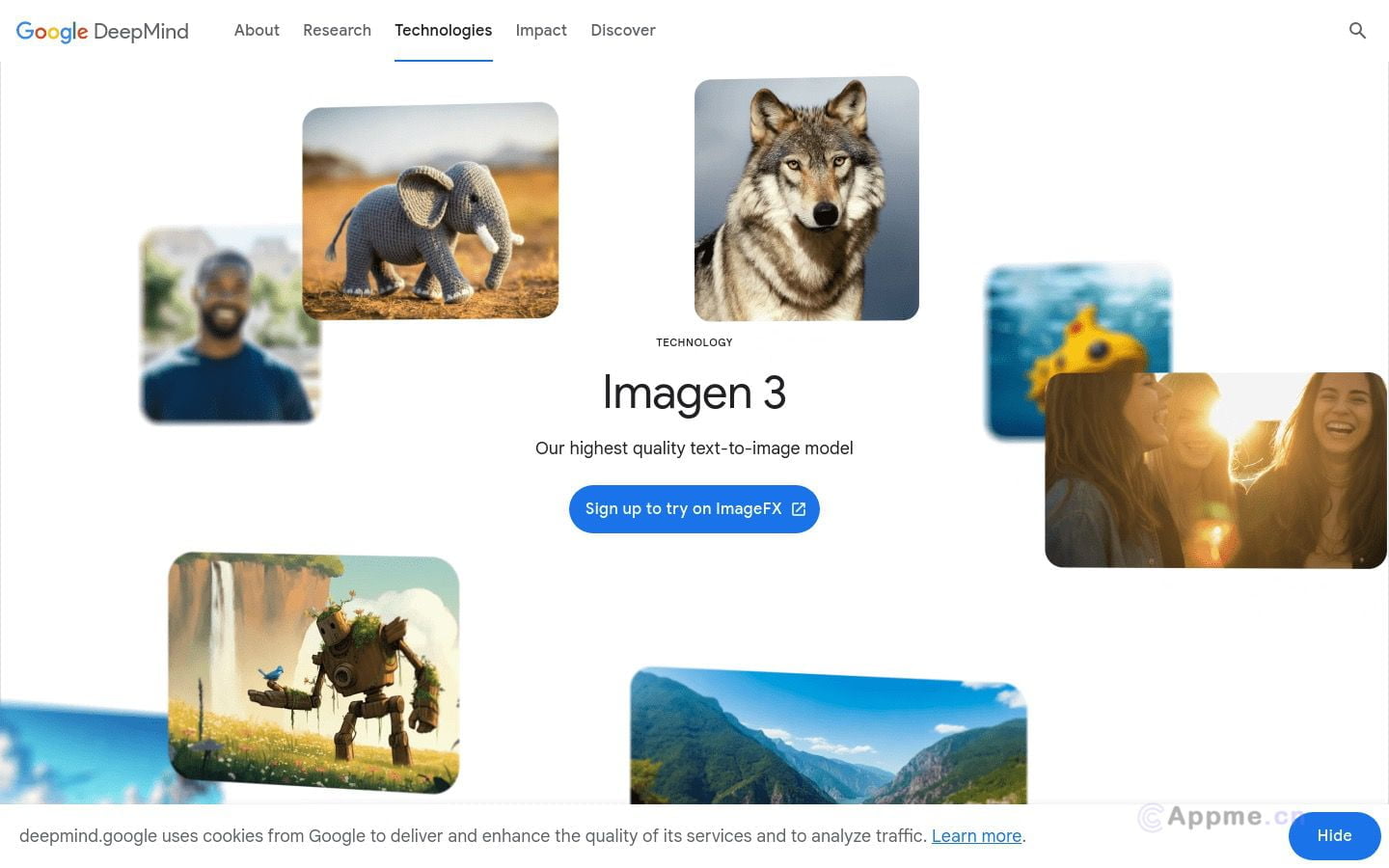
Imagen 3 by Google - 全新AI图像生成工具,质量惊艳提升300%!想获得栩栩如生的高清图像?Imagen 3凭借先进的文本理解技术和多风格适配,可根据你的创意文案快速生成精美绝伦的视觉作品。95%用户好评如潮,更有超过1000万幅作品展示Imagen 3的非凡实力。无论是快速草图还是高分辨率图像,Imagen 3都能完美胜任。立即体验这款Ai图像生成领域的颠覆性产品,释放你的视觉创造力!
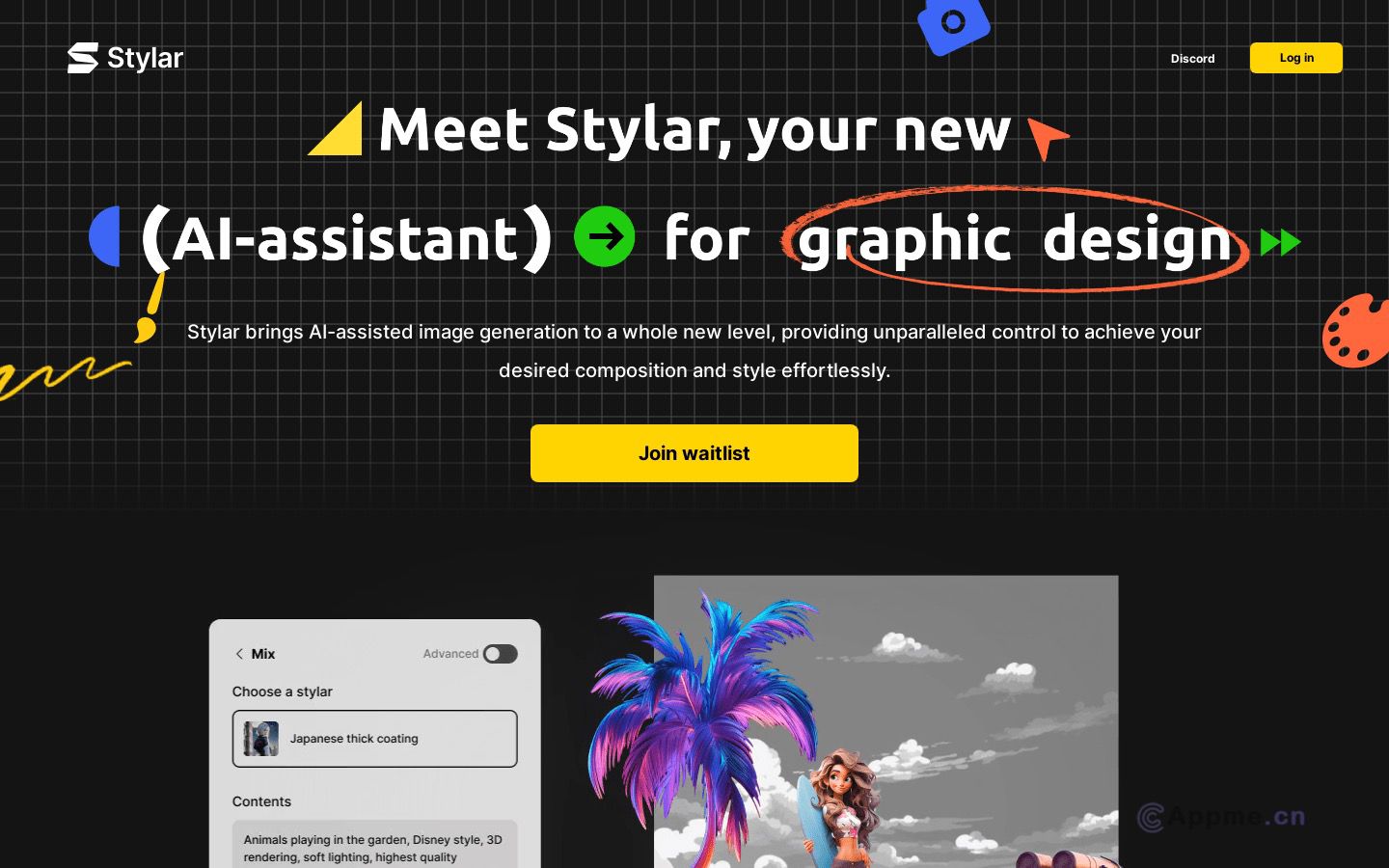


Ai模型最新工具MagicClothing,MagicClothing是一种基于潜在扩散模型(LDM)的新型网络架构,专门用于服装驱动的图像合成任务。它能够根据文本提示生成穿着特定服装的定制化角色图像,同时确保服装细节的保留和对文本提示的忠实呈现。该系统通过服装特征提取器和自注意力融合技术,实现了高度的图像可控性,并且可以与ControlNet和IP-Adapter等其他技术结合使用,以提升角色的多样性和可控性。此外,还开发了匹配点LPIPS(MP-LPIPS)评估指标,用于评价生成图像与原始服装的一致性。
Ai模型最新工具CheXagent,CheXagent是一个基于视觉语言基础模型的胸部X光解读工具。它利用临床大型语言模型来解析放射学报告,视觉编码器用于表示X光图像,并设计了一个网络来桥接视觉和语言模态。此外,CheXagent还引入了CheXbench,一个旨在系统评估基于视觉语言基础模型在8个临床相关的胸部X光解读任务上的性能的新型基准。经过广泛的定量评估和与五名专家放射科医生的定性评审,CheXagent在CheXbench任务上的表现优于先前开发的通用和医学领域的基础模型。
Ai插件最新工具ComfyUI_IPAdapter_plus,这是一个 ComfyUI 的 IPAdapter 模型参考实现。IPAdapter 是一种非常强大的模型,用于基于一个或多个参考图像进行图像到图像的条件生成。通过文本提示、控制网络和掩码,您可以生成增强图像的变体。可以将其视为单张图像的 Lora。该实现代码内存高效、运行快速,并且不会因 Comfy 更新而中断。作为开源项目,开发者欢迎捐赠以支持项目维护和新功能开发。
图像AI工具是人工智能技术在视觉领域的重要应用,涵盖了从图像生成、编辑到分析识别的全流程。这类工具的核心功能在于处理和创造各种数字图像,主要优势是提高效率、增强创意表现力和实现复杂视觉任务自动化。
代表性工具包括Midjourney和DALL-E,它们能根据文本描述生成高质量图像。在图像处理方面,Adobe Sensei融合AI技术优化Photoshop等软件的功能。这些工具广泛应用于设计、营销、艺术创作等领域,实现图像风格迁移、目标检测、人脸识别等高级功能。
随着深度学习和计算机视觉技术的进步,图像AI工具正朝着更高精度、更强通用性和更佳用户体验的方向发展。未来有望在虚拟现实、医疗影像分析等新兴领域发挥更大作用,为视觉创意和分析带来革命性变革。