
声音克隆


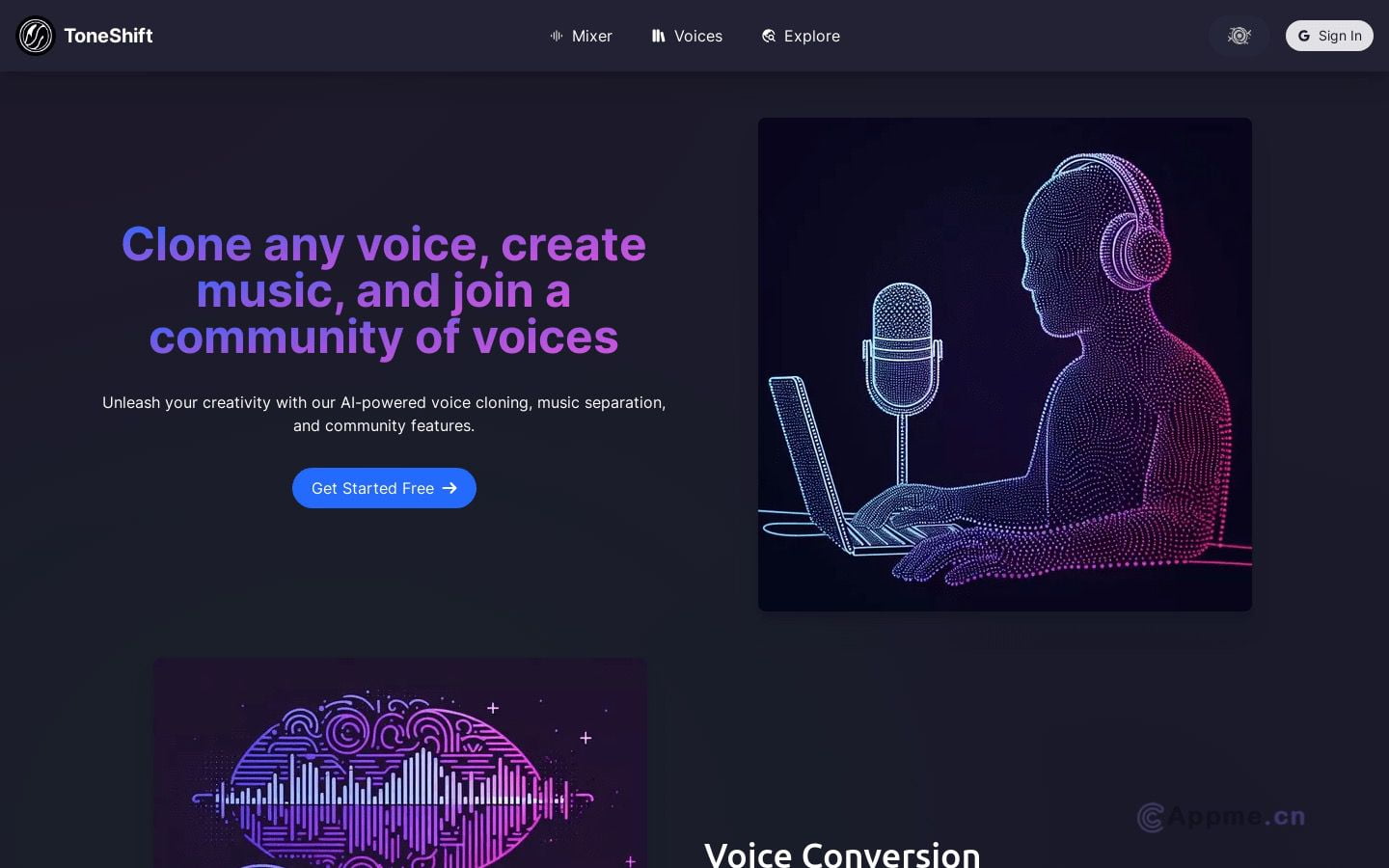
声音克隆技术是人工智能领域的一个重要分支,通过深度学习算法实现对人类声音特征的模仿和重构。这类AI工具能够分析原始音频样本,提取说话者的声音特征,并生成与原声相似度极高的合成语音。
主要应用场景包括语音助手个性化、配音制作、视频后期处理等。核心优势在于可以快速生成大量定制化语音内容,节省人力成本。代表性工具有Resemble AI和Descript的Overdub功能,它们能在短时间内克隆出自然流畅的人声。
声音克隆涉及声学模型、语音合成、音色转换等技术,需要复杂的神经网络架构支持。随着深度学习的进步,克隆音质不断提升,已接近以假乱真的程度。未来有望在更多领域得到应用,如虚拟现实、元宇宙等,但同时也带来了伦理和安全方面的挑战,需要审慎发展。