
文本嵌入
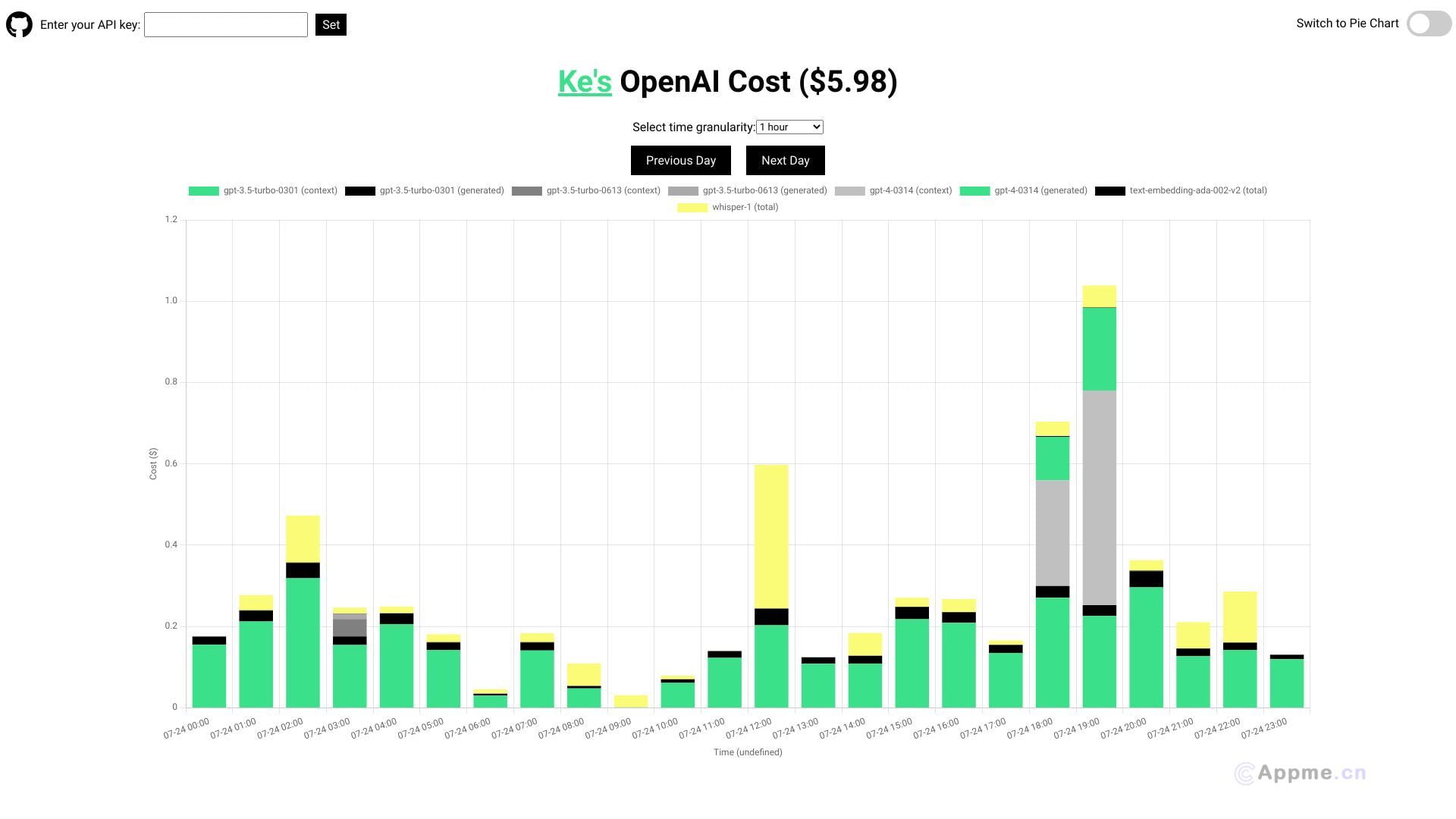
想提升检索性能?Snowflake Arctic Embed助你一臂之力!这款开源文本嵌入模型在MTEB基准测试中表现卓越,为RAG和语义搜索带来新突破。从超小型到大型,多种规格满足不同需求。Apache 2.0许可,零成本使用。想知道它如何revolutionize你的AI应用?立即免费体验,感受惊艳性能!
想要处理超长文档并实现精准检索?Jina Embeddings V2 Base是您的理想之选!这款强大的文本嵌入模型支持高达8192的序列长度,在4亿+句子对上训练,137M参数确保卓越性能。从长文档检索到语义相似度,再到RAG和LLM生成式搜索,它都能胜任。立即体验AI赋能的文本处理新境界!
文本嵌入技术是自然语言处理领域的重要分支,通过将文本转化为密集向量表示,实现语义理解和分析。这类AI工具能够捕捉词语、句子乃至整篇文档的语义信息,广泛应用于信息检索、文本分类、情感分析等场景。
代表性技术包括Word2Vec和BERT等预训练语言模型。Word2Vec通过上下文预测学习词向量,而BERT则利用双向Transformer结构获取更丰富的上下文语义。这些嵌入模型极大提升了下游NLP任务的性能。
文本嵌入的核心优势在于其语义表达能力和可迁移性。通过降维和聚类等后处理,可视化文本语义空间,发现潜在关系。此外,预训练嵌入还能迁移到特定领域,实现小样本学习。
随着大规模语言模型的发展,文本嵌入技术正向多模态、跨语言等方向拓展,有望在知识图谱构建、对话系统等更广泛的智能应用中发挥关键作用。