
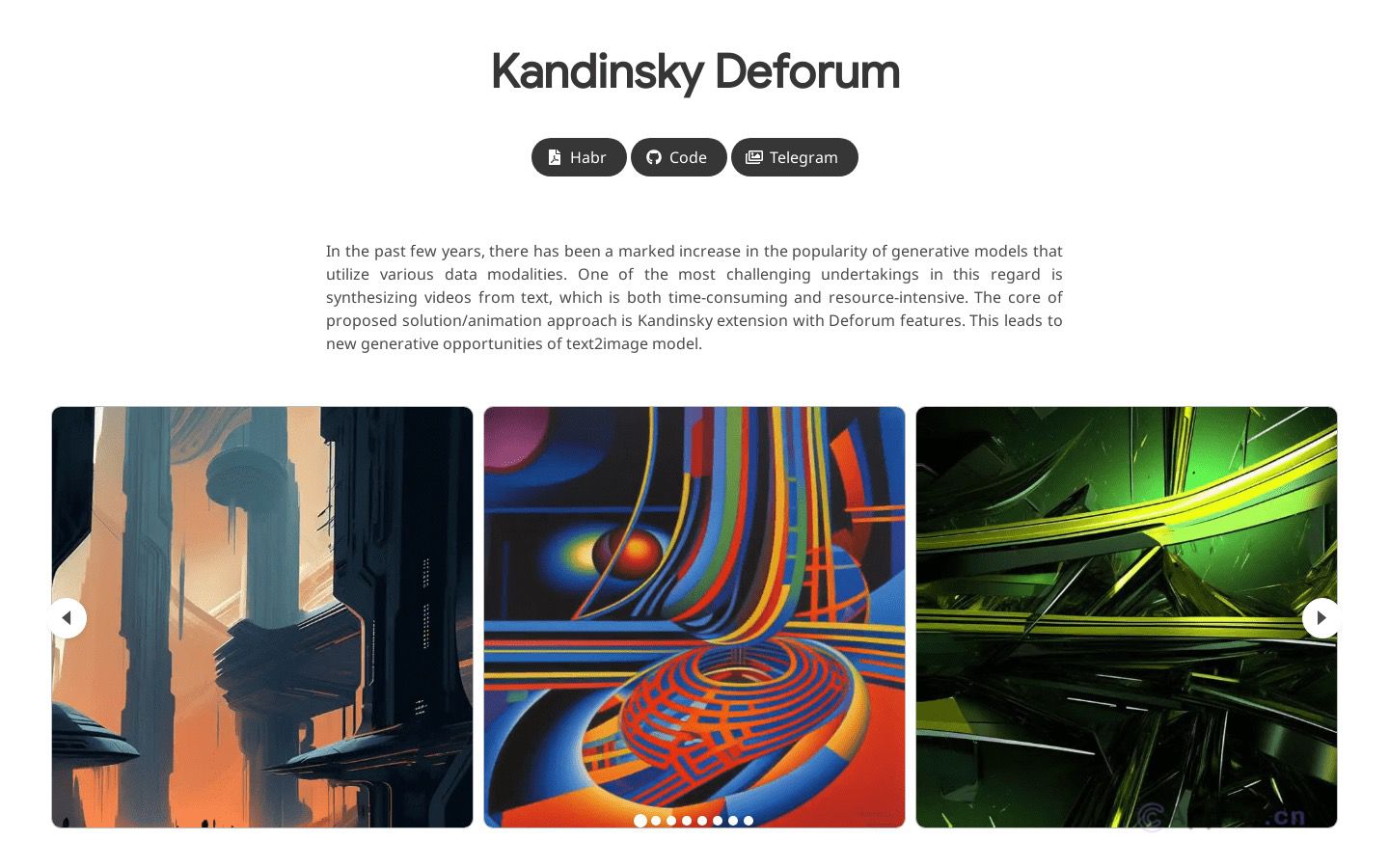
文本到图像
AI产品照片生成器是一个能够在几秒钟内生成增加销售的产品图片和照片的工具。它可以将产品图片转化为专业的产品照片,提高销售效果。使用这个工具,您可以添加AI背景,避免标签模糊或形状变化的问题。我们的AI照片生成器采用了全新的文本到图像扩散模型,专门为销售进行了训练和优化。您可以从Shopify中直接生成照片,并将其与我们的视频模板配合使用。生成的产品图片可以免费使用,并且您只需要为您真正喜欢的图片付费。
Ai网站最新工具StableIdentity,StableIdentity是一个基于大型预训练文本到图像模型的最新进展,能够实现高质量的以人为中心的生成。与现有方法不同的是,StableIdentity能够确保稳定的身份保留和灵活的可编辑性,即使在训练过程中只使用了每个主体的一张面部图像。它利用面部编码器和身份先验对输入的面部进行编码,然后将面部表示投射到一个可编辑的先验空间中。通过结合身份先验和可编辑性先验,学习到的身份可以在各种上下文中注入。此外,StableIdentity还设计了一个掩蔽的两阶段扩散损失,以提升对输入面部的像素级感知,并保持生成的多样性。大量实验证明,StableIdentity的性能优于以往的定制方法。学习到的身份还可以灵活地与ControlNet等现成模块结合使用。值得注意的是,我们是首个能够直接将从单张图像学习到的身份注入到视频/3D生成中而无需微调的方法。我们相信,StableIdentity是统一图像、视频和3D定制生成模型的重要一步。
Ai网站最新工具VLOGGER,VLOGGER是一种从单张人物输入图像生成文本和音频驱动的讲话人类视频的方法,它建立在最近生成扩散模型的成功基础上。我们的方法包括1)一个随机的人类到3D运动扩散模型,以及2)一个新颖的基于扩散的架构,通过时间和空间控制增强文本到图像模型。这种方法能够生成长度可变的高质量视频,并且通过对人类面部和身体的高级表达方式轻松可控。与以前的工作不同,我们的方法不需要为每个人训练,也不依赖于人脸检测和裁剪,生成完整的图像(而不仅仅是面部或嘴唇),并考虑到正确合成交流人类所需的广泛场景(例如可见的躯干或多样性主体身份)。
文本到图像AI工具是一类能将文字描述转化为视觉图像的先进技术。这些工具利用深度学习和生成对抗网络(GAN)等算法,从文本输入中理解语义信息,并生成相应的高质量图像。它们在创意设计、内容创作、教育培训等领域有广泛应用。
代表性工具包括DALL-E 2和Midjourney,能够生成风格多样、细节丰富的图像。这类工具的核心优势在于快速将抽象概念可视化,大幅提升创作效率。它们支持多种艺术风格和图像类型,如写实照片、插画、3D渲染等。
文本到图像技术正在不断进步,未来有望实现更精准的文本理解和图像生成。随着模型规模扩大和训练数据增加,生成图像的质量和多样性将进一步提升。这为视觉内容创作和人机交互带来了革命性的可能。