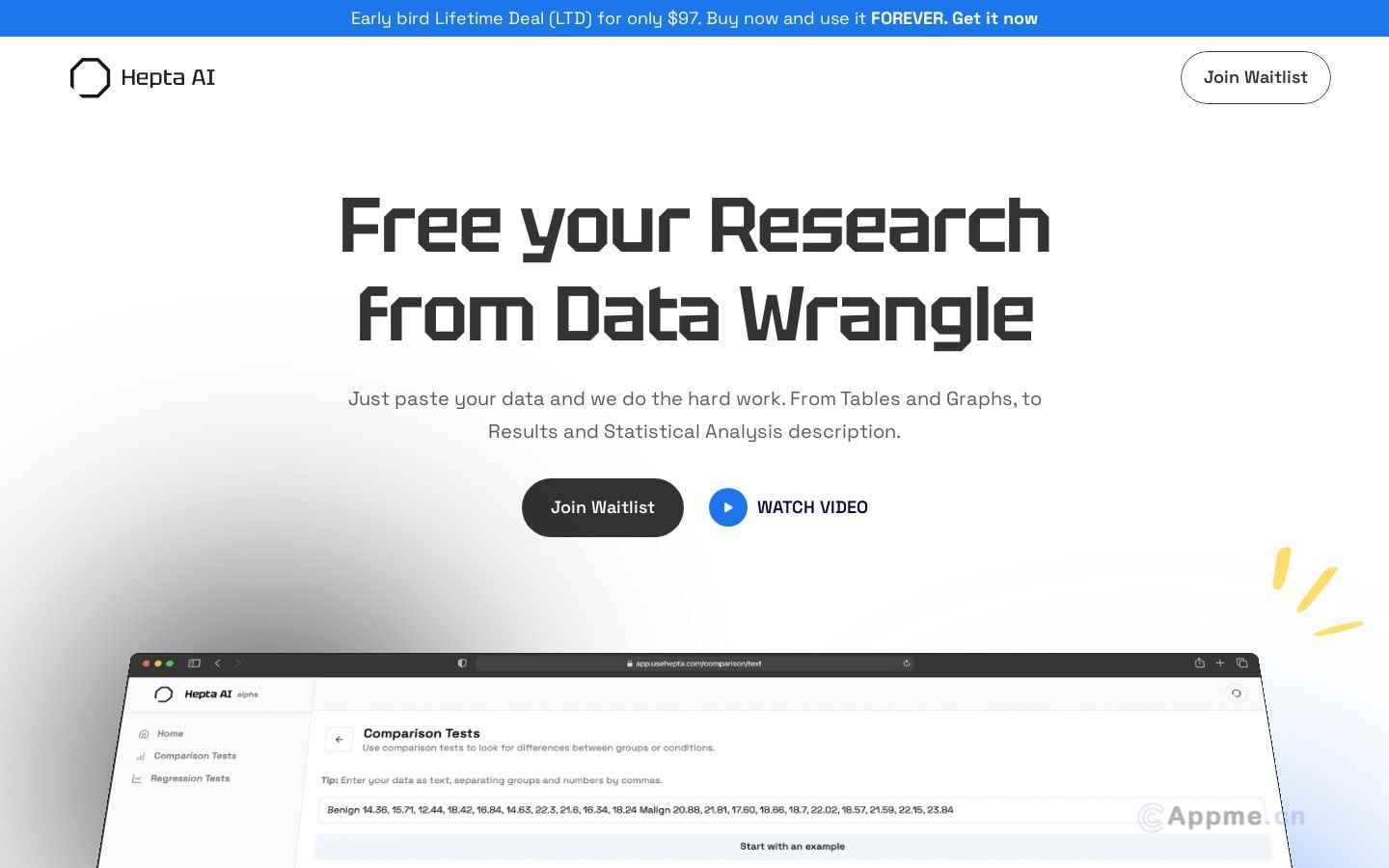
AV-HuBERT是一个专门用于音视觉语音处理的自监督表示学习框架。它在唇读、自动语音识别和音视觉语音识别等任务上实现了最先进的性能。该框架通过掩蔽多模态聚类预测来学习音视觉语音表示,提供了鲁棒的自监督学习能力。AV-HuBERT特别适合音视觉语音识别研究人员、自动语音识别系统开发者和多模态数据分析专家使用。它可应用于实验研究、多语言语音识别应用开发和语言学习工具等场景。AV-HuBERT的优势在于其音视觉语音表示学习能力、多模态聚类预测技术和自监督学习方法。对用户而言,它不仅能提高语音识别的准确性和鲁棒性,还能促进多模态语音处理技术的发展,为相关领域的研究和应用带来新的可能性。