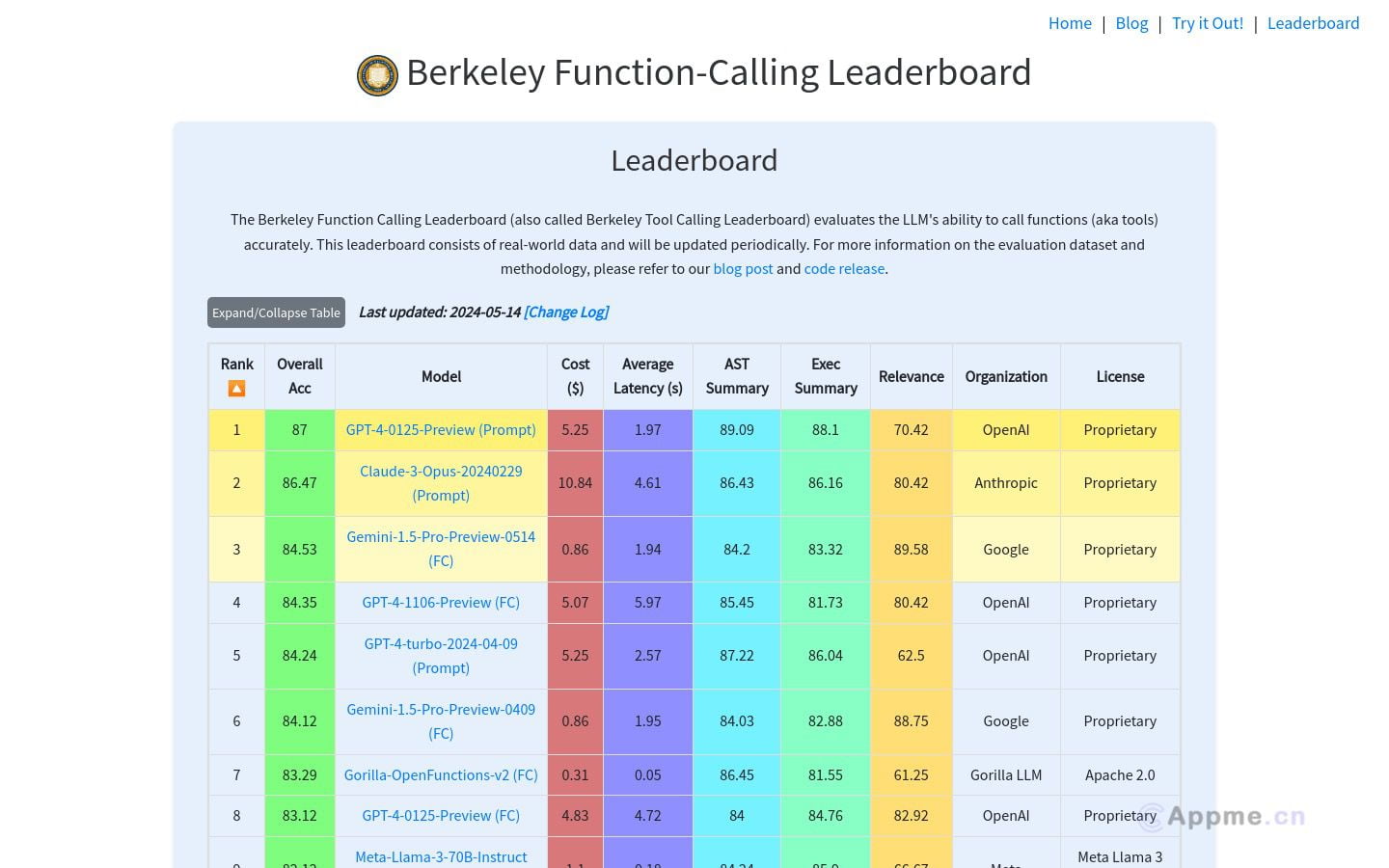
Berkeley Function-Calling Leaderboard是一个专业的在线评估平台,旨在衡量大型语言模型(LLMs)在函数调用任务上的表现。该平台基于真实世界数据,定期更新排行榜,提供详细的错误类型分析和模型比较功能。它的主要特点包括全面的评估指标、及时的技术进展反映,以及模型成本和延迟的估算。这个工具特别适合AI研究人员、开发者和对LLMs编程能力感兴趣的技术人员使用。通过使用Berkeley Function-Calling Leaderboard,用户可以深入了解不同模型的性能,选择最适合自己项目需求的AI模型,并评估其经济性和效率。它为AI领域的研究、开发和教育提供了宝贵的参考资源,有助于推动函数调用技术的进步和应用。