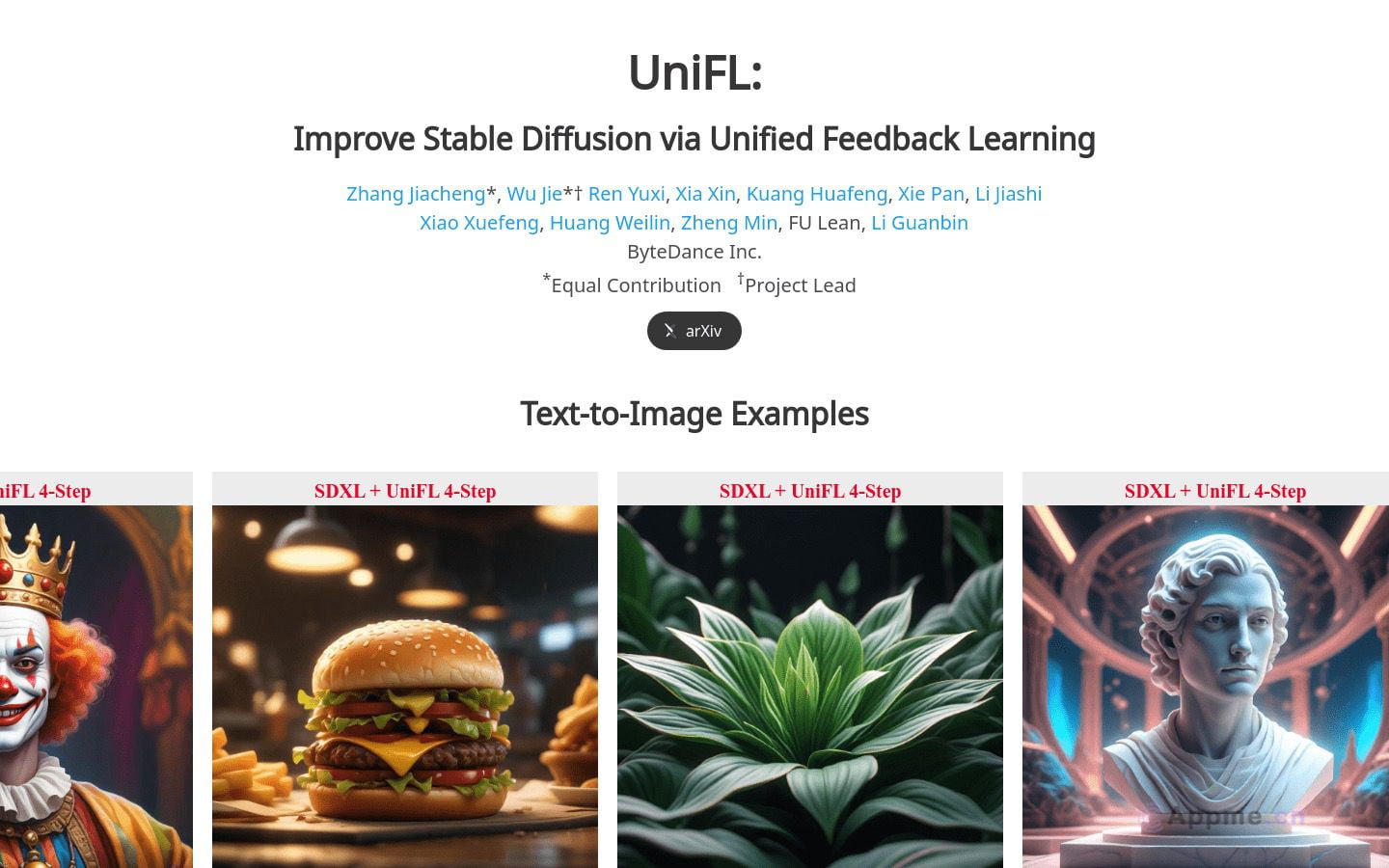
Efficient LLM是一款专为Intel GPU设计的高效大语言模型推理解决方案。它通过简化LLM解码器层、采用分段KV缓存策略和自定义Scaled-Dot-Product-Attention内核,显著提升了推理性能。与标准HuggingFace实现相比,Efficient LLM可将令牌延迟降低高达7倍,吞吐量提升高达27倍。这一突破性的性能优化使其成为自然语言处理、文本生成和对话系统等领域的理想选择。
该解决方案特别适合需要在Intel GPU上进行高效LLM推理的用户,包括研究机构、企业和开发者。它能够大幅提升模型推理速度,降低文本生成延迟,并提高对话系统的响应速度和并发处理能力。通过使用Efficient LLM,用户可以显著提高工作效率,降低计算成本,并在竞争激烈的AI应用领域中获得性能优势。