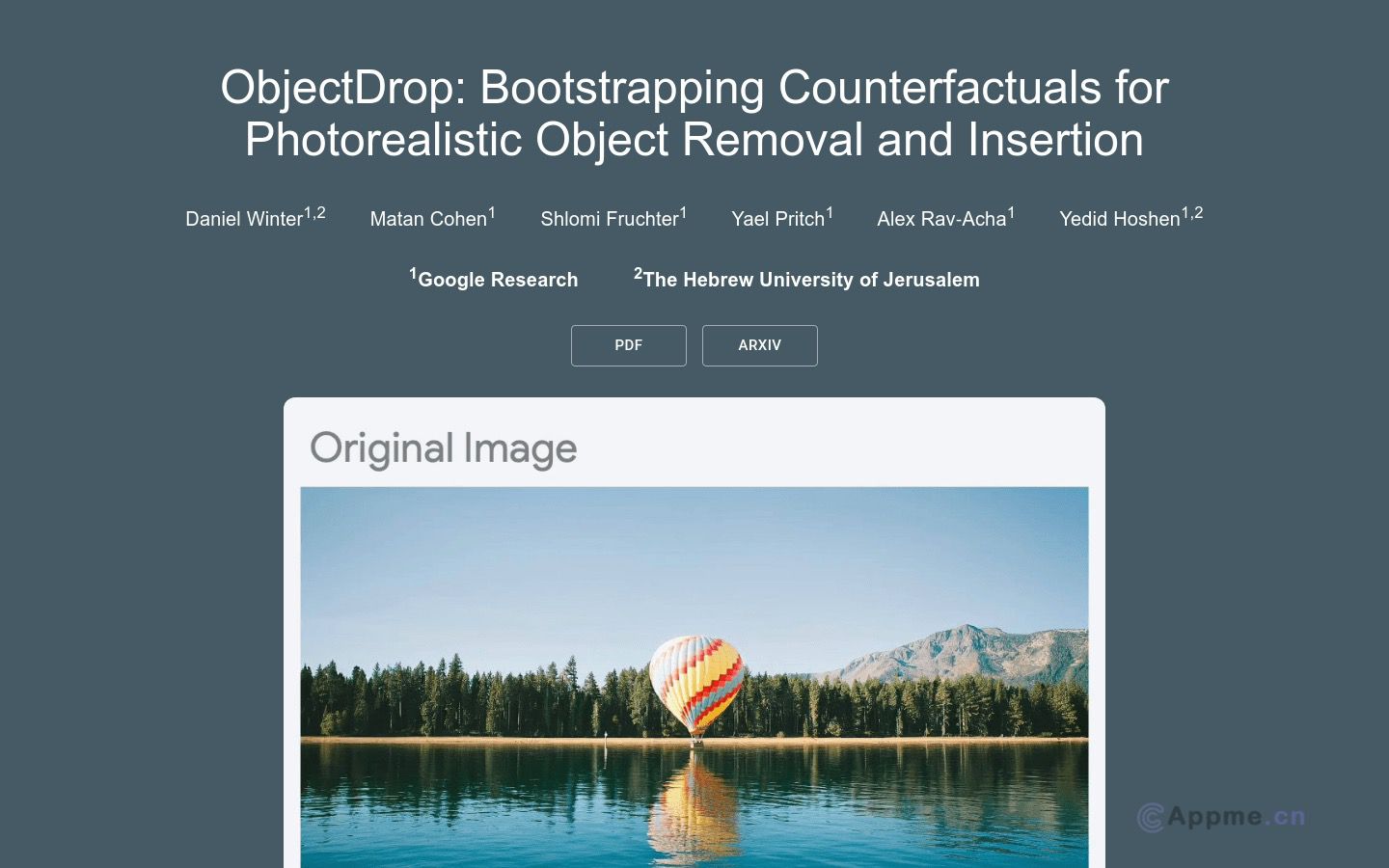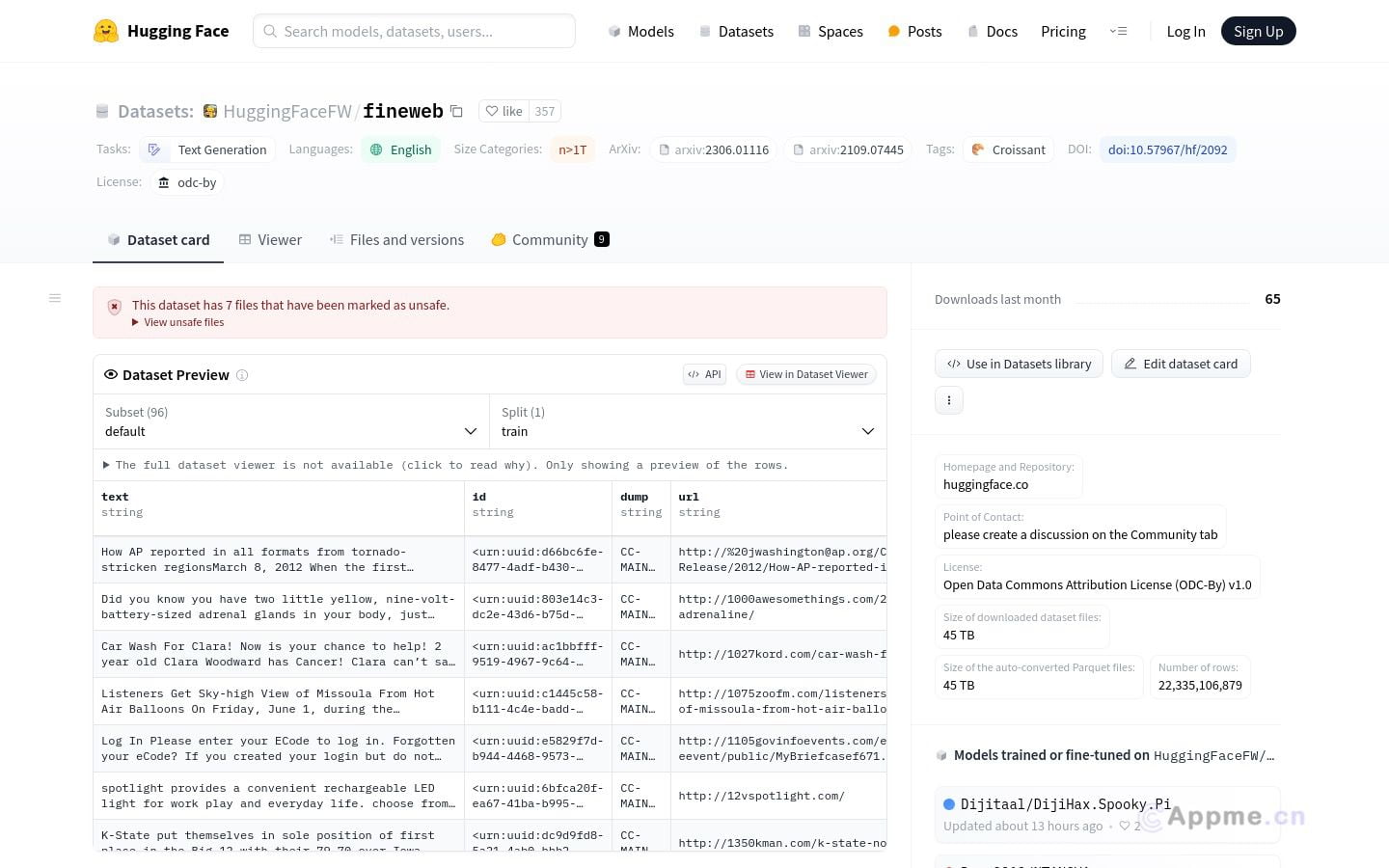
FineWeb是一款功能强大的AI网站工具,旨在为用户提供高质量的英文网页数据集。该数据集包含超过15万亿个经过清洗和去重的英文网页数据,数据来源于CommonCrawl,覆盖范围广泛。FineWeb的主要用途是为大型语言模型的预训练提供优质的数据支持,推动开源模型的发展和进步。
FineWeb的突出特点在于其数据质量高、数据量大、适用范围广。经过精心的处理和筛选,FineWeb确保了数据的高质量和可靠性。海量的数据规模为训练大型语言模型提供了充足的素材。FineWeb适用于各种自然语言处理任务,如语言理解、文本生成、情感分析等,是相关领域的研究者和开发者的理想选择。
FineWeb适合需要大量英文数据进行机器学习模型训练和优化的用户群体,特别是在自然语言处理领域。研究人员可以利用FineWeb进行语言模型预训练,以提升模型在文本生成、语言理解等任务上的性能。开发者可以用FineWeb训练聊天机器人,提高其对英文语境的理解能力,或进行情感分析研究,增强模型识别和处理英文情感表达的能力。
FineWeb为用户带来了巨大的价值和帮助。它提供了一个高质量、大规模的英文网页数据集,为训练先进的语言模型奠定了坚实的数据基础。通过使用FineWeb,研究者和开发者可以节省数据收集和处理的时间和精力,加速模型的开发和优化进程,推动自然语言处理技术的发展和应用。