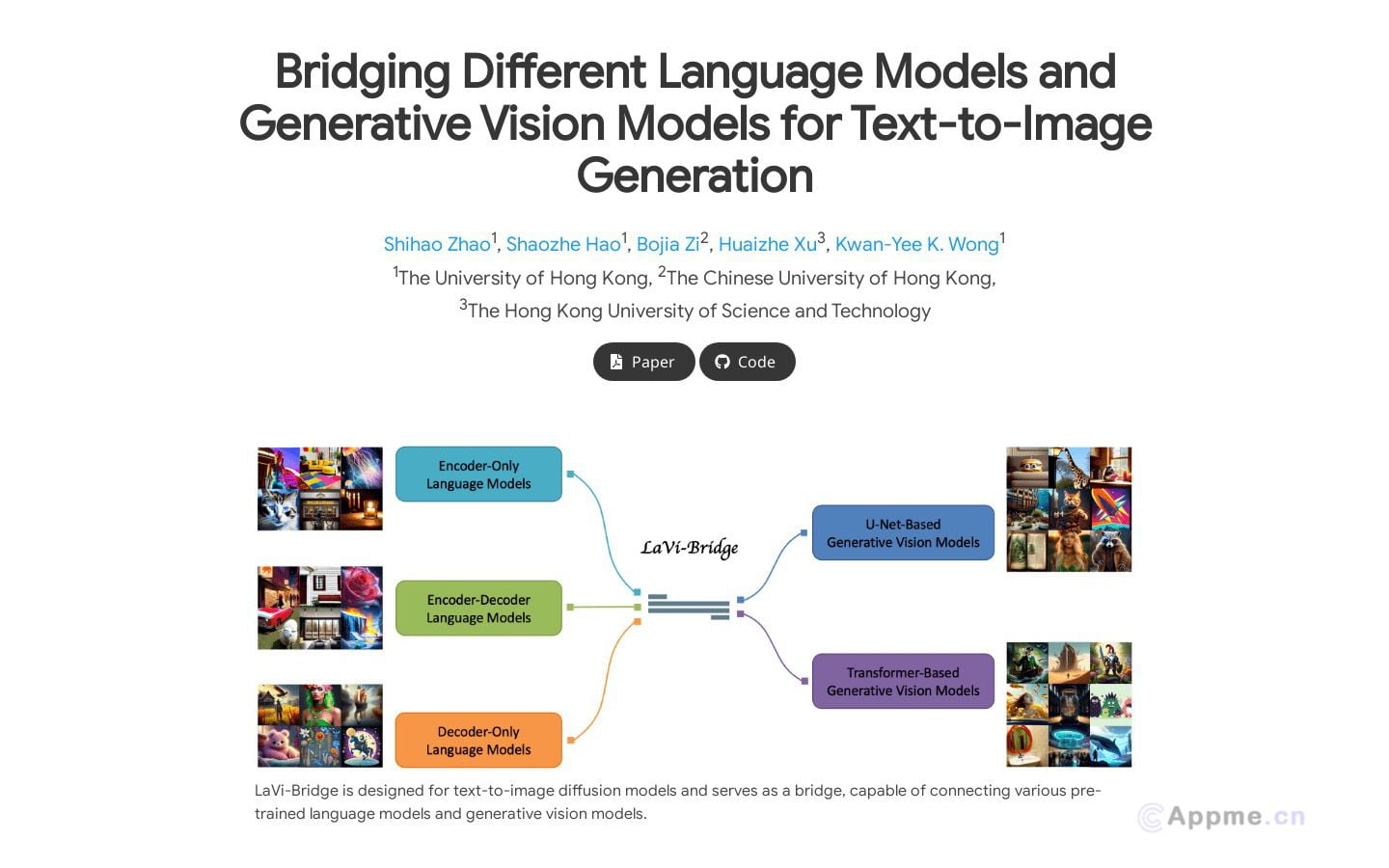
Florence-2-large是微软开发的先进视觉基础模型,能够处理广泛的视觉和视觉-语言任务。它可以通过简单的文本提示执行图像描述、目标检测和分割等任务,展现了强大的多任务学习能力。该模型采用序列到序列的架构,在零样本和微调设置中均表现出色,是一个极具竞争力的视觉基础模型。
Florence-2-large适合需要进行图像分析和理解的开发者和研究人员使用。它可以应用于社交媒体自动图片描述、电商商品图片分类、自动驾驶中的道路识别等多个场景。模型的主要特色包括图像描述生成、目标检测、图像分割、密集区域描述、区域提议和OCR等功能。
对于用户而言,Florence-2-large提供了一个强大的工具,可以大幅提高图像分析和处理的效率,为视觉识别相关的研究和应用带来重要价值。