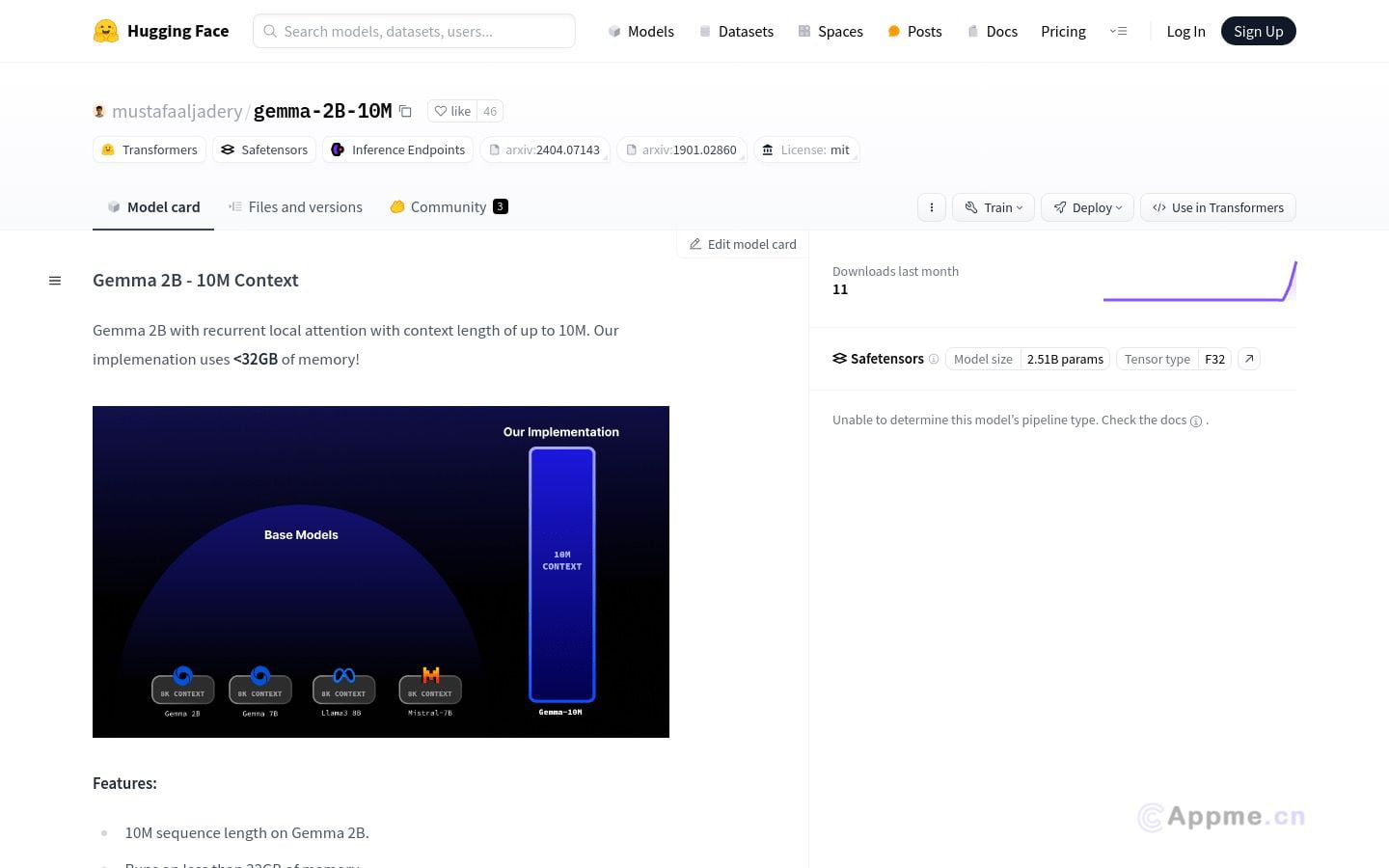
Gemma-2B-10M是一款创新的大规模语言模型,专为处理长文本而设计。它能在内存使用低于32GB的情况下处理长达10M的序列,采用循环局部注意力技术实现O(N)内存复杂度,大幅提升了性能和效率。该模型特别适合需要处理大量文本数据的研究人员、开发者和企业用户,可用于长文本生成、摘要、翻译等多种语言任务。其优化的资源使用和CUDA加速使其在大规模文本处理中表现卓越。用户可通过简单的步骤快速部署和使用,轻松实现复杂的文本分析和生成任务。Gemma-2B-10M为用户提供了强大的文本处理能力,帮助提高工作效率,降低资源消耗,是处理大规模语言任务的理想工具。