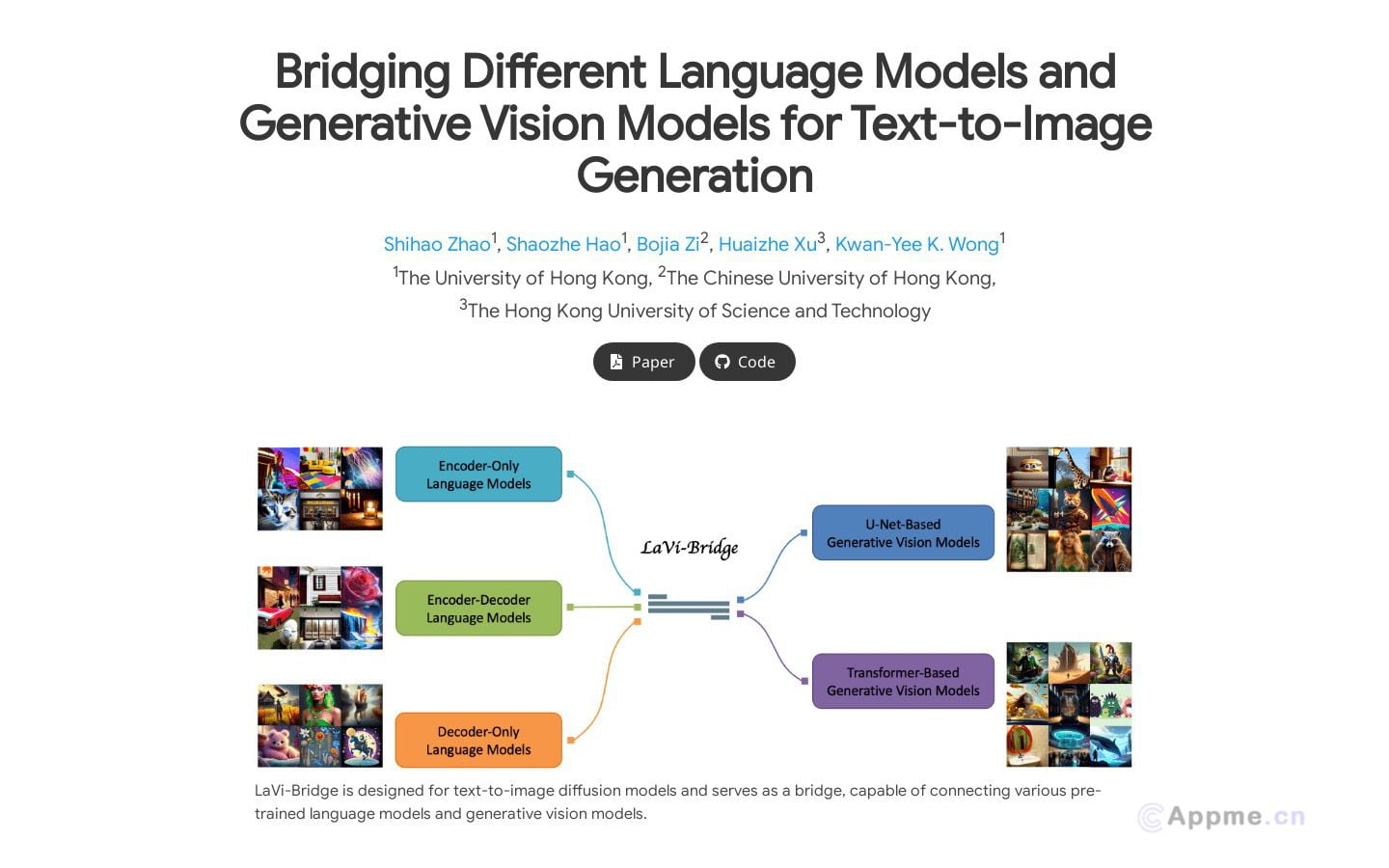
llama3v是一款开源的视觉语言多模态学习模型工具,基于最先进的Llama3 8B语言模型和siglip-so400m视觉模型。它主要用于图像识别、文本生成以及多模态数据的联合处理和分析。
该工具的特点是通过添加投影层,将图像特征映射到语言模型的嵌入空间,增强了模型对图像理解的能力。同时,llama3v在Huggingface上提供了预训练权重,支持快速的本地推理,并且代码开源。
llama3v非常适合需要处理图文多模态数据的研究人员和开发者使用。研究人员可以用它进行图像和文本的联合分析研究,开发者可以用它实现图像识别、自动标注等功能,企业可以用它进行产品图像的智能分类和检索。
使用llama3v,用户可以更高效、智能地处理图像和文本数据,大大提升工作效率。同时,由于其出色的多模态理解能力,用户可以利用它获得更准确、更全面的数据分析结果,为科研和生产应用带来更大的价值。