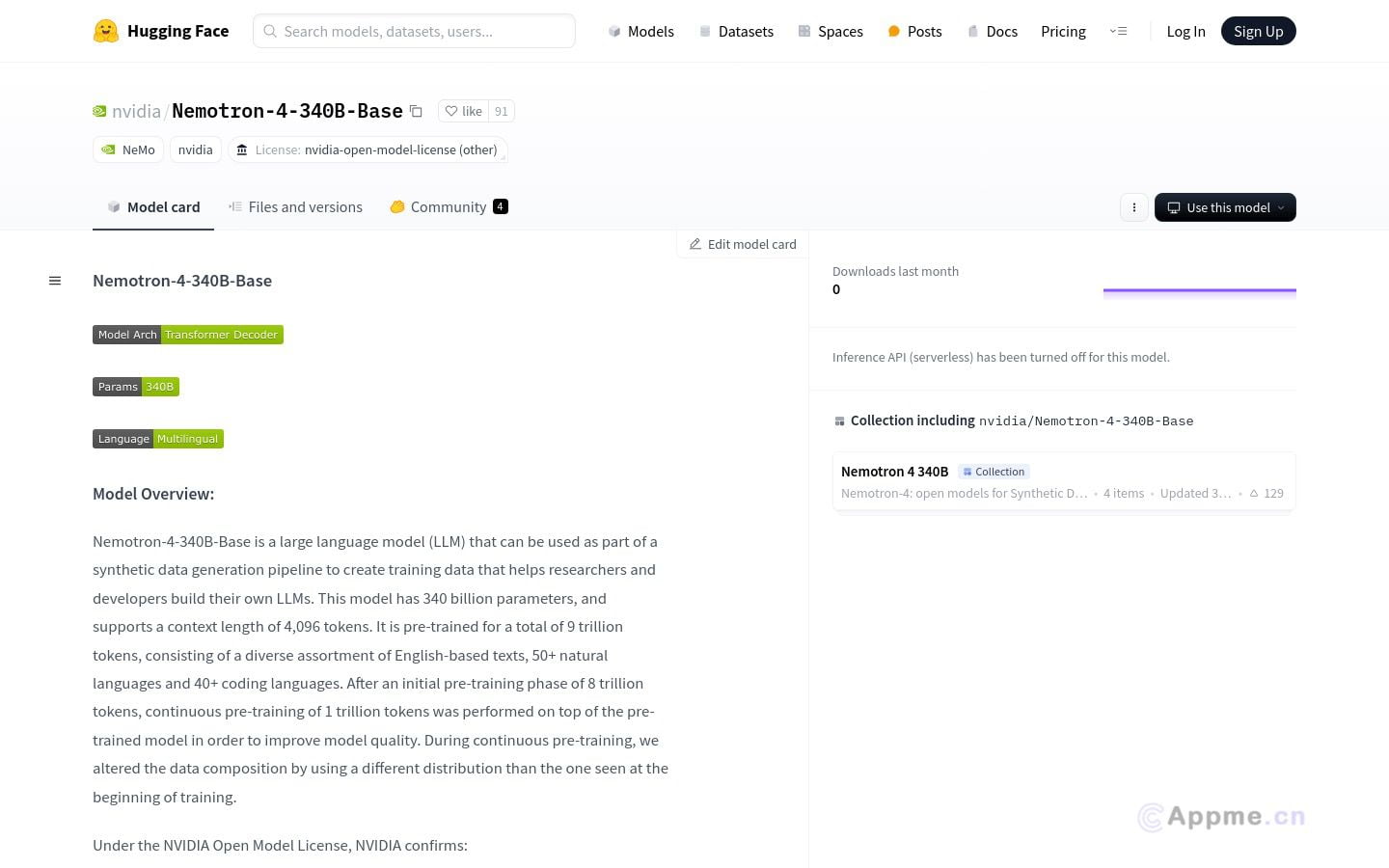
Nemotron-4-340B-Base是NVIDIA开发的强大大型语言模型,拥有3400亿参数和4096个token的上下文长度。该模型经过9万亿token的预训练,涵盖50多种自然语言和40多种编程语言,可用于生成合成数据,帮助研究人员和开发者构建自己的大型语言模型。Nemotron-4-340B-Base的主要优势在于其庞大的参数规模和广泛的语言覆盖范围,使其能够处理复杂的自然语言和编程任务。该模型特别适合AI研究人员、语言模型开发者和需要处理多语言数据的机构使用。通过NVIDIA的开放许可,用户可以自由地进行商业应用和创建派生模型,为AI技术的创新和应用提供了宝贵的资源和平台。