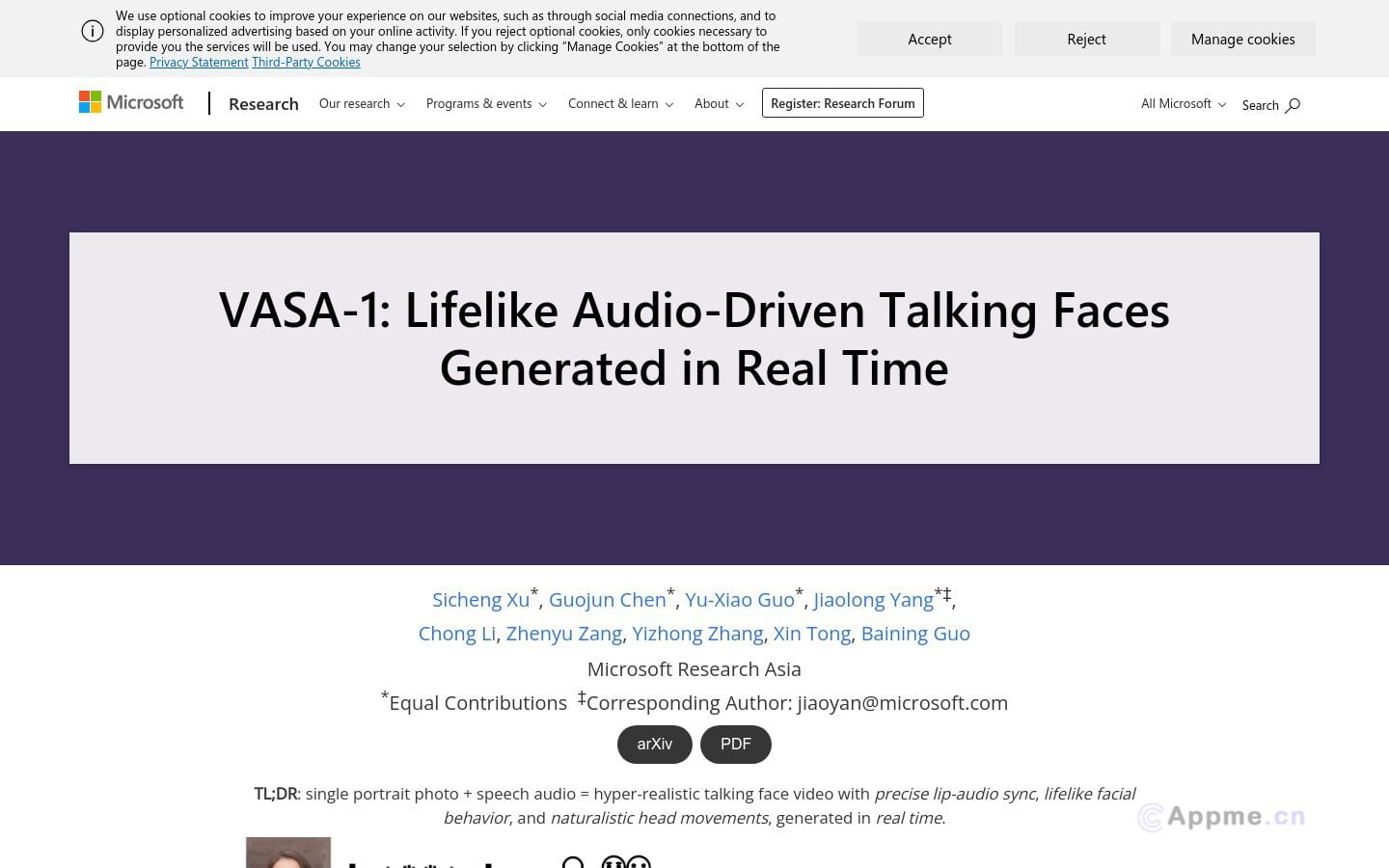
VASA-1是微软研究院开发的一款先进AI模型,专注于实时生成与音频匹配的逼真人脸动画。它利用深度学习算法,能根据输入的语音内容自动生成相应的口型和面部表情,为用户提供全新的交互体验。VASA-1的主要优势在于高度逼真的生成效果和实时响应能力,使虚拟角色能更自然地与用户互动。该技术适用于需要虚拟人物实时互动的场景,如虚拟助手、在线教育、视频会议和游戏角色动画等。VASA-1为这些领域带来了革新性的解决方案,大大提升了虚拟交互的真实感和沉浸感,为用户创造了更加生动、自然的数字体验。虽然定价策略尚未公布,但预计将提供免费试用版本,让用户亲身体验这一创新技术。