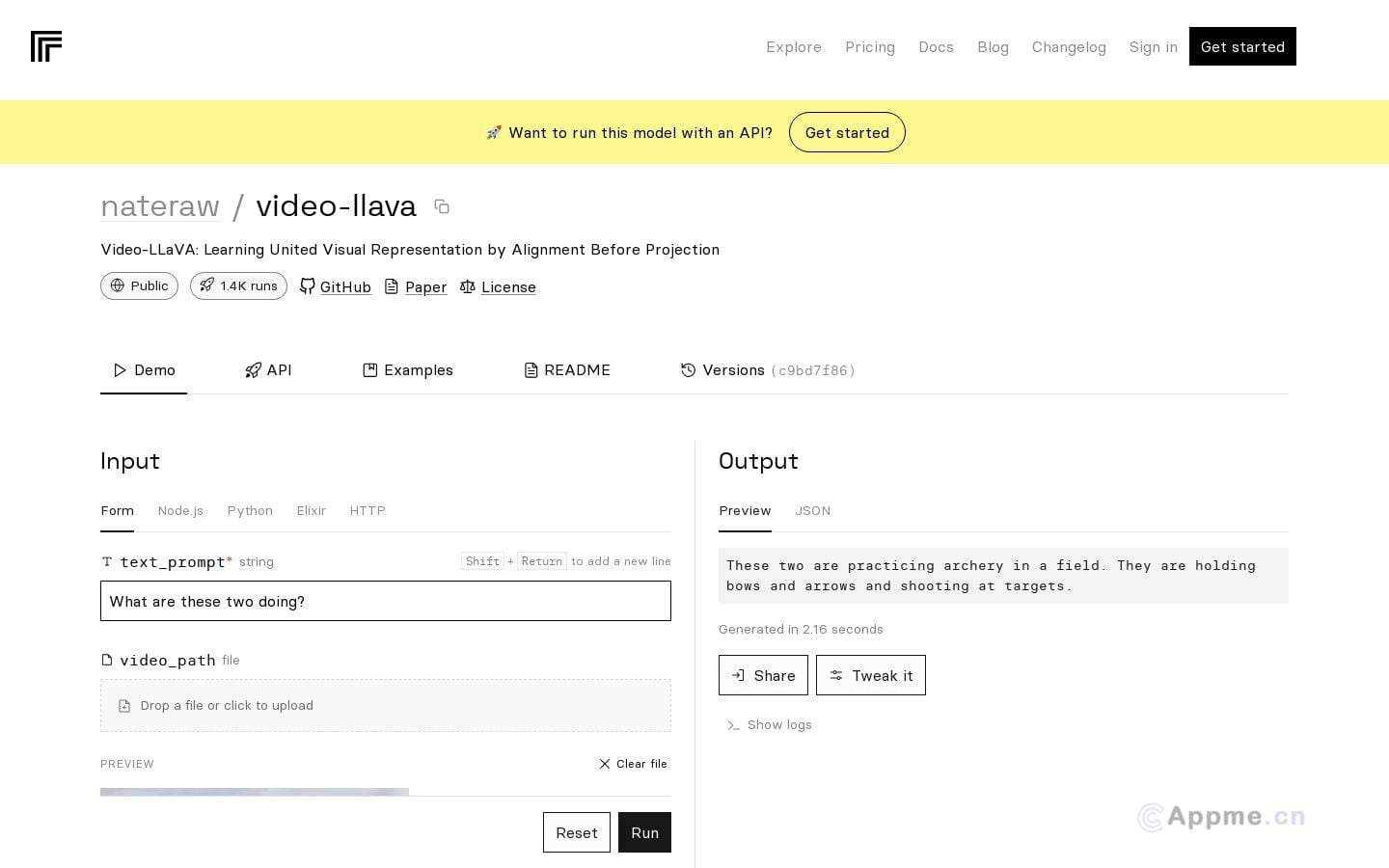
Video-LLaVA是一款先进的AI视觉理解工具,专注于学习联合视觉表示。通过创新的对齐前投影训练方法,该模型能够有效地将视频和图像表示进行对齐,从而实现更深入的视觉理解。Video-LLaVA的突出特点是其高效的学习和推理速度,使其在处理大规模视频数据时表现卓越。
这款软件特别适合从事视频处理和视觉任务的专业人士,如计算机视觉研究人员、视频分析师和人工智能开发者。它可应用于多种场景,包括视频分类、图像检索和目标跟踪等。
对于用户而言,Video-LLaVA带来的最大价值在于其强大的视觉理解能力和高效性。它不仅可以提高视频分析的准确度,还能显著加快处理速度,从而帮助用户更快、更准确地完成复杂的视觉任务,提升工作效率和研究质量。