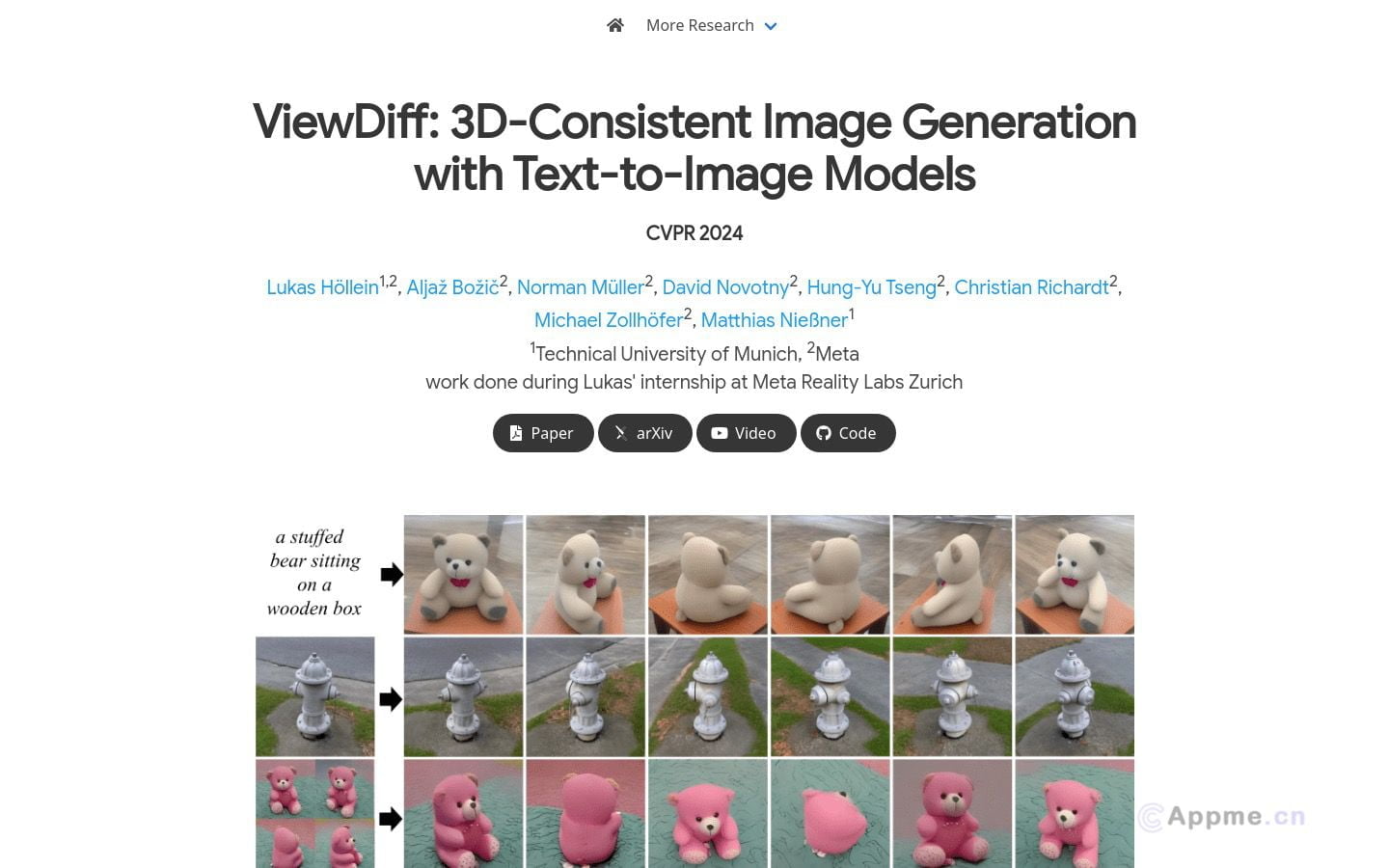
ViewDiff是一款创新的AI工具,利用预训练的文本到图像模型作为先验知识,从真实世界数据中学习生成多视角一致的3D图像。它采用了独特的技术架构,在U-Net网络中加入了3D体积渲染和跨帧注意力层,能够在单个去噪过程中高效生成视觉质量出众、3D一致性极佳的图像。
ViewDiff的主要特点包括:基于预训练模型生成3D一致图像,单次去噪即可实现多视角一致,以及优于现有方法的视觉效果和3D一致性。它非常适合需要生成逼真3D物体图像的用户,如3D建模从业者、图像合成爱好者、虚拟现实内容创作者等。
使用ViewDiff,用户可以轻松地根据文本描述生成形状和质地多样的3D物体,并将其自然融入真实世界环境。同时,给定单个物体图像,ViewDiff就能生成该物体在不同视角下的一致图像。它为3D内容生成提供了一种便捷高效的新思路,有望在3D设计、虚拟现实等领域发挥重要作用,为用户带来创作灵感和效率的提升。