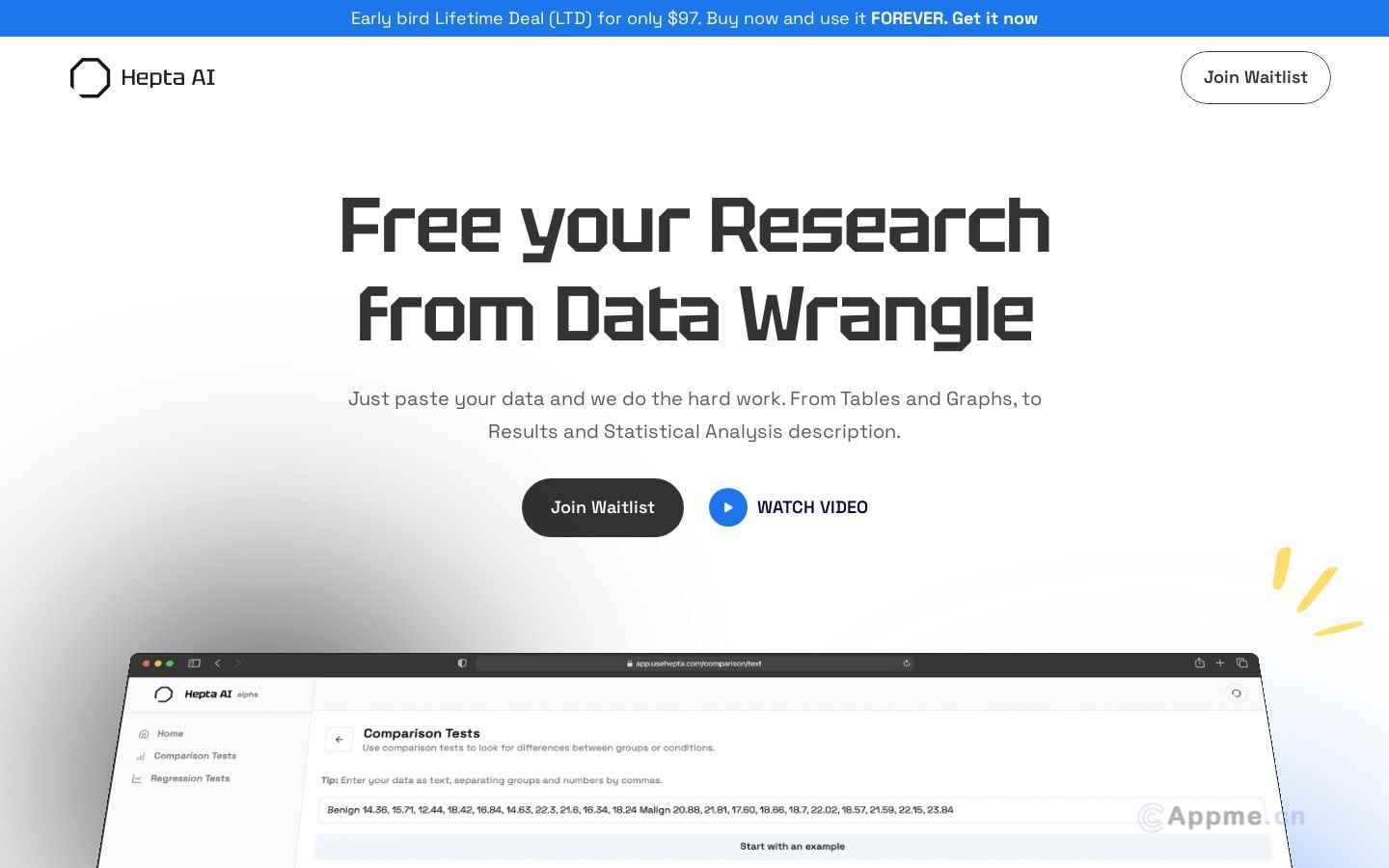
VSP-LLM是一款创新的人工智能工具,结合了视觉语音处理和大型语言模型的优势。它主要用于视觉语音识别和翻译,能将输入视频映射到语言模型的潜在空间,实现多任务处理。该软件采用自监督学习方法,并通过独特的去重技术和低秩适配器实现高效训练。VSP-LLM特别适合需要多语言语音识别、跨语言视频内容理解和实时语音翻译的用户群体。它可应用于国际会议实时翻译、多语言视频内容分析、以及语言教育等场景,为用户提供准确、高效的语音识别和翻译服务。通过maximizing上下文建模能力,VSP-LLM能够显著提升跨语言交流和内容理解的效率,为全球化交流和信息获取带来巨大便利。